

💧Liquid LFM2.5: Ausführen & Finetunen
Führe LFM2.5 Instruct und Vision lokal auf deinem Gerät aus und finetune sie!
Dynamische GGUFs
16-Bit Instruct
⚙️ Gebrauchsanleitung
Chat-Vorlagenformat
Werkzeugnutzung
🖥️ LFM2.5-1.2B-Instruct ausführen
📖 llama.cpp Anleitung (GGUF)
🦥 Feinabstimmung von LFM2.5 mit Unsloth
Unsloth-Konfiguration für LFM2.5
Trainingseinrichtung
Speichern und Export
🎉 llama-server Bereitstellung & Deployment
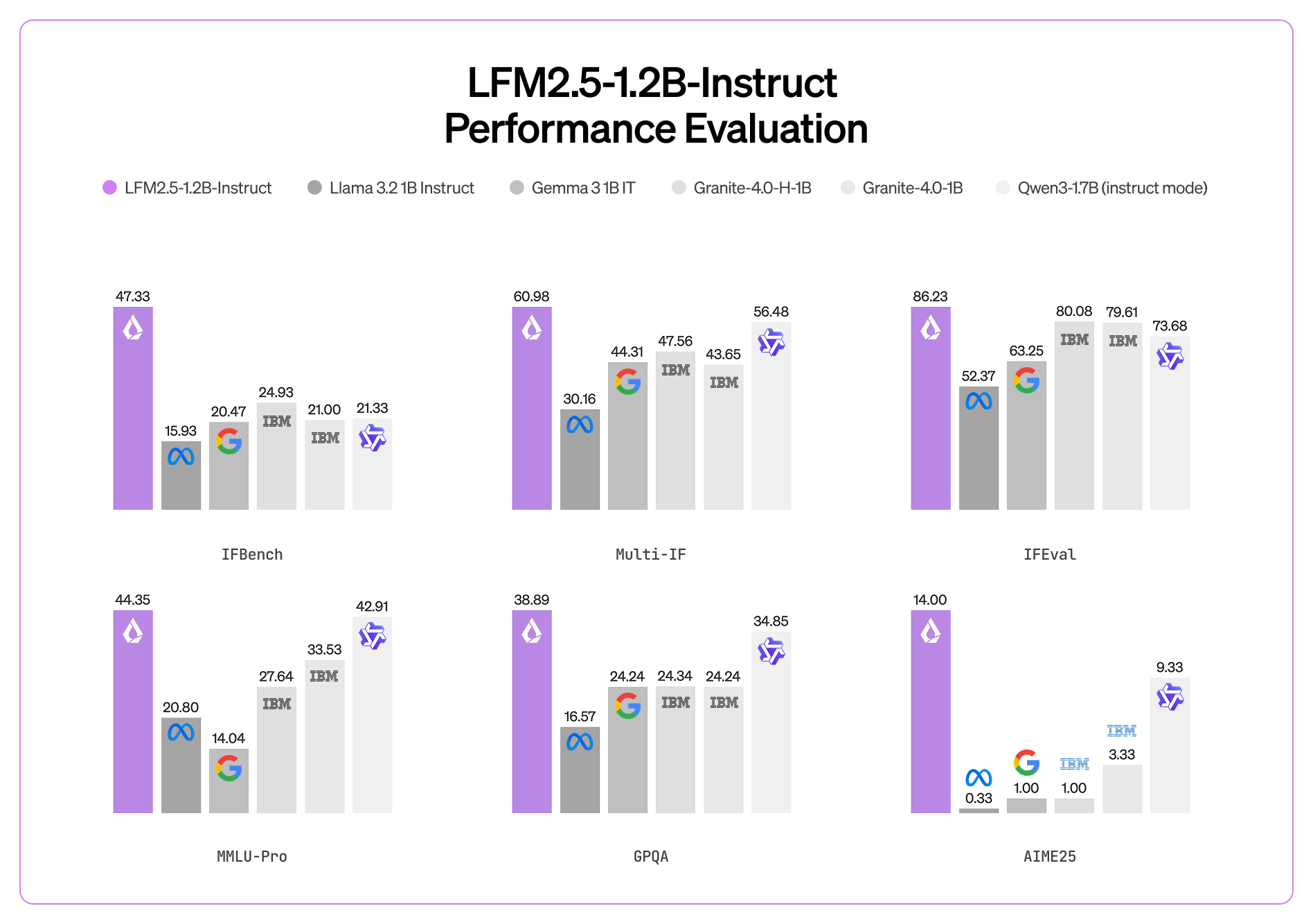
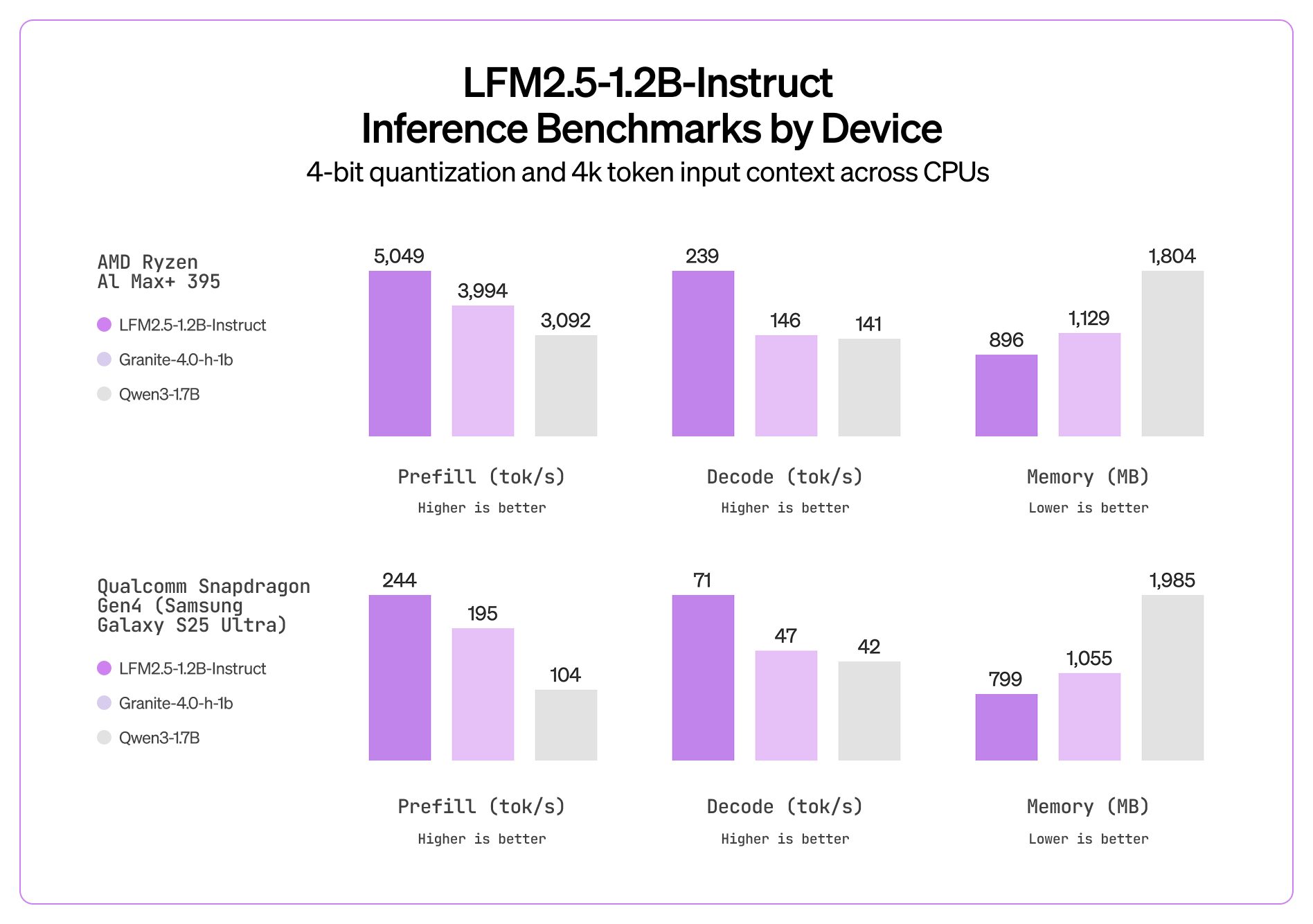
📊 Benchmarks
💧 Liquid LFM2.5-1.2B-VL Anleitung
Dynamische GGUFs
16-Bit Instruct
⚙️ Nutzungsanleitung
Chat-Vorlagenformat
🖥️ LFM2.5-VL-1.6B ausführen
📖 llama.cpp Anleitung (GGUF)
🦥 Feinabstimmung von LFM2.5-VL mit Unsloth
Unsloth-Konfiguration für LFM2.5
Trainingseinrichtung
Speichern und Export
📊 Benchmarks
Modell
MMStar
MM-IFEval
BLINK
InfoVQA (Val)
OCRBench (v2)
RealWorldQA
MMMU (Val)
MMMB (Durchschnitt)
Multilinguales MMBench (Durchschnitt)
📚 Ressourcen
Zuletzt aktualisiert
War das hilfreich?