

📱Wie man LLMs auf deinem iOS- oder Android-Telefon ausführt und bereitstellt
Tutorial zum Finetunen deines eigenen LLM und zur Bereitstellung auf deinem Android oder iPhone mit ExecuTorch.
Wir freuen uns, zu zeigen, wie Sie LLMs trainieren können und dann sie lokal bereitstellen zu Android-Telefone und iPhones. Wir haben mit ExecuTorch von PyTorch & Meta zusammengearbeitet, um einen optimierten Workflow mit quantisierungsbewusstem Training (QAT) zu erstellen und sie dann direkt auf Edge-Geräte bereitzustellen. Mit Unsloth, TorchAO und ExecuTorch zeigen wir, wie Sie:
Die gleiche Technologie (ExecuTorch) nutzen, die Meta einsetzt, um Milliarden auf Instagram, WhatsApp zu unterstützen
Qwen3-0.6B lokal bereitzustellen auf Pixel 8 und iPhone 15 Pro mit ~40 Tokens/s
QAT via TorchAO anwenden, um 70% der Genauigkeit wiederherzustellen
Datenschutz zuerst erhalten, sofortige Antworten und Offline-Funktionen
Verwenden Sie unser kostenloses Colab-Notebook um Qwen3 0.6B feinzujustieren und für die Telefonbereitstellung zu exportieren
Qwen3-4B auf einem iPhone 15 Pro bereitgestellt

Qwen3-0.6B läuft mit ~40 Tokens/s

🦥 Ihr Modell trainieren
Wir unterstützen Qwen3, Gemma3, Llama3, Qwen2.5, Phi4 und viele andere Modelle für die Telefonbereitstellung! Folgen Sie dem kostenloses Colab-Notebook für die Bereitstellung von Qwen3-0.6B:
Aktualisieren Sie zuerst Unsloth und installieren Sie TorchAO und Executorch.
Dann verwenden Sie einfach qat_scheme = "phone-deployment" um zu kennzeichnen, dass wir es auf ein Telefon bereitstellen möchten. Beachten Sie, dass wir auch full_finetuning = True für vollständiges Finetuning setzen!
Wir verwenden qat_scheme = "phone-deployment" tatsächlich verwenden wir qat_scheme = "int8-int4" unter der Haube, um Unsloth/TorchAO QAT zu ermöglichen, das simuliert INT8 dynamische Aktivierungsquantisierung mit INT4 Gewichtsquantisierung für Linear-Schichten während des Trainings (über Fake-Quantisierungsoperationen), während die Berechnungen in 16 Bit verbleiben. Nach dem Training wird das Modell in eine echte quantisierte Version konvertiert, sodass das On-Device-Modell kleiner ist und typischerweise die Genauigkeit besser erhält als naive PTQ.
Nach dem Finetuning wie im Colab-Notebookbeschrieben, speichern wir es dann in einer .pte Datei via Executorch:
🏁 Bereitstellung nach dem Training
Und nun mit Ihrer qwen3_0.6B_model.pte Datei, die etwa 472MB groß ist, können wir sie bereitstellen! Wählen Sie Ihr Gerät und legen Sie direkt los:
Run LLMs on your Phone – Xcode-Route, Simulator oder Gerät
Run LLMs on your Phone – Kommandozeilen-Route, kein Studio erforderlich
iOS-Bereitstellung
Tutorial, um Ihr Modell auf iOS zum Laufen zu bringen (getestet auf einem iPhone 16 Pro, funktioniert aber auch auf anderen iPhones). Sie benötigen ein physisches macOS-Gerät, das Xcode 15 ausführen kann.
Einrichtung der macOS-Entwicklungsumgebung
Xcode & Command Line Tools installieren
Installieren Sie Xcode aus dem Mac App Store (muss Version 15 oder neuer sein)
Öffnen Sie das Terminal und überprüfen Sie Ihre Installation:
xcode-select -pInstallieren Sie die Command Line Tools und akzeptieren Sie die Lizenz:
xcode-select --installsudo xcodebuild -license accept
Starten Sie Xcode zum ersten Mal und installieren Sie bei Aufforderung alle zusätzlichen Komponenten
Wenn Sie aufgefordert werden, Plattformen auszuwählen, wählen Sie iOS 18 und laden Sie es für den Simulatorzugriff herunter
Überprüfen Sie, ob alles funktioniert: xcode-select -p
Sie sollten einen Pfad sehen. Wenn nicht, wiederholen Sie Schritt 3.

Einrichtung eines Apple-Developer-Kontos
Nur für physische Geräte!
Überspringen Sie diesen Abschnitt vollständig, wenn Sie nur den iOS-Simulator verwenden. Sie benötigen nur für die Bereitstellung auf einem physischen iPhone ein kostenpflichtiges Entwicklerkonto.
Erstellen Sie Ihre Apple ID
Haben Sie noch keine Apple ID? Hier registrieren.
Fügen Sie Ihr Konto zu Xcode hinzu
Öffnen Sie Xcode
Navigieren Sie zu Xcode → Einstellungen → Accounts
Klicken Sie auf die + Schaltfläche und wählen Sie Apple ID
Melden Sie sich mit Ihrer regulären Apple ID an

Melden Sie sich beim Apple Developer Program an
ExecuTorch erfordert die Fähigkeit "increased-memory-limit", die ein kostenpflichtiges Entwicklerkonto benötigt:
Besuchen Sie developer.apple.com
Melden Sie sich mit Ihrer Apple ID an
Melden Sie sich beim Apple Developer Program an
Richten Sie die ExecuTorch Demo-App ein
Beziehen Sie den Beispielcode:
In Xcode öffnen
Öffnen Sie
apple/etLLM.xcodeprojin XcodeWählen Sie in der oberen Symbolleiste
iPhone 16 ProSimulator als ZielgerätDrücken Sie Play (▶️), um zu bauen und auszuführen
🎉 Erfolg! Die App sollte jetzt im Simulator starten. Sie funktioniert noch nicht, wir müssen Ihr Modell hinzufügen.

Bereitstellen im Simulator
Kein Entwicklerkonto erforderlich.
Bereiten Sie Ihre Modell-Dateien vor
Stoppen Sie den Simulator in Xcode (drücken Sie die Stop-Taste)
Navigieren Sie zu Ihrem HuggingFace Hub Repo (falls nicht lokal gespeichert)
Laden Sie diese zwei Dateien herunter:
qwen3_0.6B_model.pte(Ihr exportiertes Modell)tokenizer.json (der Tokenizer)
Erstellen Sie einen gemeinsamen Ordner im Simulator
Klicken Sie auf die virtuelle Home-Taste im Simulator
Öffnen Sie die Dateien-App → Durchsuchen → Auf meinem iPhone
Tippen Sie auf die Ellipse (•••)-Schaltfläche und erstellen Sie einen neuen Ordner mit dem Namen
Qwen3test
Übertragen Sie Dateien mit dem Terminal
Wenn Sie den Ordner sehen, führen Sie Folgendes aus:
Laden & Chatten
Kehren Sie zur etLLM-App im Simulator zurück. Tippen Sie, um sie zu starten.

Laden Sie das Modell und den Tokenizer aus dem Qwen3test-Ordner

Beginnen Sie, mit Ihrem feinabgestimmten Modell zu chatten! 🎉

Bereitstellung auf Ihrem physischen iPhone
Erste Geräteeinrichtung
Verbinden Sie Ihr iPhone per USB mit Ihrem Mac
Entsperren Sie Ihr iPhone und tippen Sie auf "Diesem Computer vertrauen"
Öffnen Sie in Xcode Fenster → Geräte und Simulatoren
Warten Sie, bis Ihr Gerät links erscheint (es kann kurz "Vorbereiten" anzeigen)
Xcode-Signing konfigurieren
Fügen Sie Ihr Apple-Konto hinzu: Xcode → Einstellungen → Accounts →
+Klicken Sie im Projekt-Navigator auf das etLLM-Projekt (blaues Symbol)
Wählen Sie etLLM unter TARGETS
Gehen Sie zur Registerkarte Signing & Capabilities
Aktivieren Sie "Automatically manage signing"
Wählen Sie Ihr Team aus dem Dropdown-Menü

Ändern Sie die Bundle-Identifier in etwas Einzigartiges (z. B. com.ihreName.etLLM). Das behebt 99% der Fehler mit Provisioning-Profilen
Fügen Sie die erforderliche Fähigkeit hinzu
Klicken Sie weiterhin bei Signing & Capabilities auf + Capability
Suchen Sie nach "Increased Memory Limit" und fügen Sie es hinzu
Build & Run
Wählen Sie in der oberen Symbolleiste Ihr physisches iPhone im Geräteselector
Drücken Sie Play (▶️) oder Cmd + R
Vertrauen Sie dem Entwicklerzertifikat
Ihr erster Build wird fehlschlagen—das ist normal!
Gehen Sie auf Ihrem iPhone zu Einstellungen → Datenschutz & Sicherheit → Entwicklermodus
Schalten Sie ihn ein
Zustimmen und Hinweise akzeptieren
Starten Sie das Gerät neu, kehren Sie zu Xcode zurück und drücken Sie erneut Play
Der Entwicklermodus erlaubt Xcode, Apps auf Ihrem iPhone auszuführen und zu installieren
Modelldateien auf Ihr iPhone übertragen

Sobald die App läuft, öffnen Sie den Finder auf Ihrem Mac
Wählen Sie Ihr iPhone in der Seitenleiste aus
Klicken Sie auf die Dateien-Registerkarte
Erweitern Sie etLLM
Ziehen Sie Ihre .pte- und tokenizer.json-Dateien direkt in diesen Ordner
Seien Sie geduldig! Diese Dateien sind groß und können einige Minuten dauern
Laden & Chatten
Wechseln Sie auf Ihrem iPhone zurück zur etLLM-App

Laden Sie das Modell und den Tokenizer über die App-Oberfläche

Ihr feinabgestimmtes Qwen3 läuft jetzt nativ auf Ihrem iPhone!

Android-Bereitstellung
Diese Anleitung beschreibt, wie man die ExecuTorch Llama-Demo-App auf einem Android-Gerät baut und installiert (getestet mit Pixel 8, funktioniert aber auch auf anderen Android-Telefonen) unter Verwendung einer Linux-/Mac-Kommandozeilenumgebung. Dieser Ansatz minimiert Abhängigkeiten (kein Android Studio erforderlich) und verlagert den aufwändigen Build-Prozess auf Ihren Computer.
Anforderungen
Stellen Sie sicher, dass Ihr Entwicklungsrechner Folgendes installiert hat:
Java 17 (Java 21 ist oft Standard, kann aber Build-Probleme verursachen)
Git
Wget / Curl
Android Command Line Tools
Anleitung zur Installation und Einrichtung von
adbauf Ihrem Android und Ihrem Computer
Verifikation
Überprüfen Sie, ob Ihre Java-Version 17.x entspricht:
Wenn dies nicht der Fall ist, installieren Sie es unter Ubuntu/Debian:
Setzen Sie es dann als Standard oder exportieren Sie JAVA_HOME:
Wenn Sie ein anderes OS oder eine andere Distribution verwenden, sollten Sie möglicherweise diese Anleitung oder einfach Ihr Lieblings-LLM bitten, Sie durchzuführen.
Schritt 1: Android SDK & NDK installieren
Richten Sie eine minimale Android-SDK-Umgebung ohne das komplette Android Studio ein.
1. Erstellen Sie das SDK-Verzeichnis:
Android Command Line Tools installieren
Schritt 2: Umgebungsvariablen konfigurieren
Fügen Sie diese zu Ihrer ~/.bashrc oder ~/.zshrc:
Laden Sie sie neu:
Schritt 3: SDK-Komponenten installieren
ExecuTorch benötigt bestimmte NDK-Versionen.
Setzen Sie die NDK-Variable:
Schritt 4: Code holen
Wir verwenden das executorch-examples Repository, das die aktualisierte Llama-Demo enthält.
Schritt 5: Häufige Kompilationsprobleme beheben
Beachten Sie, dass der aktuelle Code diese Probleme nicht hat, wir hatten sie jedoch zuvor und sie könnten für Sie hilfreich sein:
Behebe "SDK Location not found":
Erstellen Sie eine local.properties Datei, um Gradle explizit zu sagen, wo sich das SDK befindet:
Behebe cannot find symbol Fehler:
Der aktuelle Code verwendet eine veraltete Methode getDetailedError(). Patchen Sie es mit diesem Befehl:
Schritt 6: APK bauen
Dieser Schritt kompiliert die App und die nativen Bibliotheken.
Wechseln Sie zum Android-Projekt:
Bauen mit Gradle (setzen Sie explizit
JAVA_HOMEauf 17, um Toolchain-Fehler zu vermeiden):Hinweis: Der erste Lauf dauert ein paar Minuten.
Die schließlich erzeugte apk finden Sie unter:
Schritt 7: Auf Ihrem Android-Gerät installieren
Sie haben zwei Optionen, um die App zu installieren.
Option A: Mit ADB (kabelgebunden/wireless)
Wenn Sie adb Zugriff auf Ihr Telefon haben:
Option B: Direkte Dateitransfer
Wenn Sie auf einer entfernten VM sind oder kein Kabel haben:
Laden Sie die app-debug.apk an einen Ort hoch, von dem Sie sie auf dem Telefon herunterladen können
Laden Sie sie auf Ihrem Telefon herunter
Tippen Sie zum Installieren (aktivieren Sie "Installation aus unbekannten Quellen zulassen", falls aufgefordert).
Schritt 8: Modelldateien übertragen
Die App benötigt die .pte Modell- und Tokenizer-Dateien.
Dateien übertragen: Verschieben Sie Ihre model.pte und tokenizer.bin (oder tokenizer.model) in den Speicher Ihres Telefons (z. B. Downloads-Ordner).
LlamaDemo App öffnen: Starten Sie die App auf Ihrem Telefon.
Modell auswählen
Tippen Sie auf Einstellungen (Zahnrad-Symbol) oder den Dateiauswähler.
Navigieren Sie zu Ihrem Download-Ordner.
Wählen Sie Ihre .pte-Datei aus.
Wählen Sie Ihre Tokenizer-Datei aus.
Fertig! Sie können nun direkt auf Ihrem Gerät mit dem LLM chatten.
Fehlerbehebung
Build schlägt fehl? Prüfen Sie java -version. Es MUSS 17 sein.
Modell lädt nicht? Stellen Sie sicher, dass Sie sowohl das
.pteALS AUCH dastokenizer.App stürzt ab? Gültige
.pteDateien müssen speziell für ExecuTorch exportiert werden (normalerweise XNNPACK-Backend für die CPU).
Modell auf Ihr Telefon übertragen
Derzeit executorchllama App, die wir gebaut haben, unterstützt das Laden des Modells nur aus einem bestimmten Verzeichnis auf Android, das leider nicht über normale Dateimanager erreichbar ist. Aber wir können die Modellausgaben mit adb in dieses Verzeichnis speichern.
Stellen Sie sicher, dass adb richtig läuft und verbunden ist
Wenn Sie über Wireless-Debugging verbunden sind, sehen Sie so etwas:

Oder wenn Sie über ein Kabel verbunden sind:

Wenn Sie dem Computer keine Berechtigungen zum Zugriff auf Ihr Telefon gegeben haben:

Müssen Sie auf Ihrem Telefon einen Popup-Dialog prüfen, der so aussieht (den Sie zulassen möchten)

Sobald dies erledigt ist, ist es Zeit, den Ordner zu erstellen, in den wir die .pte und tokenizer.json Dateien legen müssen.
Erstellen Sie das genannte Verzeichnis auf dem Telefonpfad.
Überprüfen Sie, dass das Verzeichnis korrekt erstellt wurde.
Schieben Sie den Inhalt in das genannte Verzeichnis. Dies kann je nach Computer, Verbindung und Telefon ein paar Minuten oder länger dauern. Bitte seien Sie geduldig.

Öffnen Sie die
executorchllamademoApp, die Sie in Schritt 5 installiert haben, und tippen Sie dann auf das Zahnrad oben rechts, um die Einstellungen zu öffnen.Tippen Sie auf den Pfeil neben Model, um den Auswähler zu öffnen und ein Modell auszuwählen. Wenn Sie ein leeres weißes Dialogfeld ohne Dateinamen sehen, ist Ihr ADB-Model-Push wahrscheinlich fehlgeschlagen - wiederholen Sie diesen Schritt. Beachten Sie auch, dass anfänglich "kein Modell ausgewählt" angezeigt werden kann.
Nachdem Sie ein Modell ausgewählt haben, sollte die App den Modell-Dateinamen anzeigen.


Wiederholen Sie nun das Gleiche für den Tokenizer. Klicken Sie auf den Pfeil neben dem Tokenizer-Feld und wählen Sie die entsprechende Datei aus.

Möglicherweise müssen Sie den Modelltyp auswählen, abhängig davon, welches Modell Sie hochladen. Qwen3 ist hier ausgewählt.

Sobald Sie beide Dateien ausgewählt haben, klicken Sie auf die Schaltfläche "Load Model".

Sie kehren zum ursprünglichen Bildschirm mit dem Chat-Fenster zurück, und es kann "model loading" anzeigen. Je nach RAM und Speichergeschwindigkeit Ihres Telefons kann das Laden ein paar Sekunden dauern.

Sobald "successfully loaded model" angezeigt wird, können Sie beginnen, mit dem Modell zu chatten. Et Voila, Sie haben jetzt ein LLM, das nativ auf Ihrem Android-Telefon läuft!

📱ExecuTorch treibt Milliarden an
ExecuTorch ermöglicht On-Device-ML-Erfahrungen für Milliarden von Menschen auf Instagram, WhatsApp, Messenger und Facebook. Instagram Cutouts verwendet ExecuTorch, um editierbare Sticker aus Fotos zu extrahieren. In verschlüsselten Anwendungen wie Messenger ermöglicht ExecuTorch geräteinterne, datenschutzbewusste Spracherkennung und Übersetzung. ExecuTorch unterstützt mehr als ein Dutzend Hardware-Backends über Apple, Qualcomm, ARM und Metas Quest 3 und Ray Bans.
Weitere Modellunterstützung
Alle Qwen 3 Dense-Modelle (Qwen3-0.6B, Qwen3-4B, Qwen3-32B usw.)
Alle Gemma 3 Modelle (Gemma3-270M, Gemma3-4B, Gemma3-27B usw.)
Alle Llama 3 Modelle (Llama 3.1 8B, Llama 3.3 70B Instruct usw.)
Qwen 2.5, Phi 4 Mini-Modelle und vieles mehr!
Sie können die kostenloses Colab-Notebook für Qwen3-0.6B anpassen, um die Telefonbereitstellung für eines der oben genannten Modelle zu ermöglichen!
Qwen3 0.6B Haupt-Notebook für Telefonbereitstellung
Funktioniert mit Gemma 3
Funktioniert mit Llama 3
Gehen Sie zu unserer Unsloth-Notebooks Seite für alle anderen Notebooks!
🌵 Bereitstellung auf Cactus für Telefone
Cactus ist eine Open-Source-Inferenz-Engine für mobile Geräte, Macs und ARM-Chips wie Raspberry Pi.
Bei INT8 läuft Cactus
Qwen3-0.6BundLFM2-1.2Bmit60-70 toks/secauf dem iPhone 17 Pro,13-18 toks/secauf dem günstigen Pixel 6a.Aufgaben-spezifische INT8-Tunes von
Gemma3-270merreichen150 toks/secauf dem iPhone 17 Pro und23 toks/secauf dem Raspberry Pi.
Schnellstart
1. Trainieren (Google Colab / GPU)
Verwenden Sie das bereitgestellte Notebook oder Ihr eigenes Unsloth-Trainingsskript:
2. Cactus einrichten
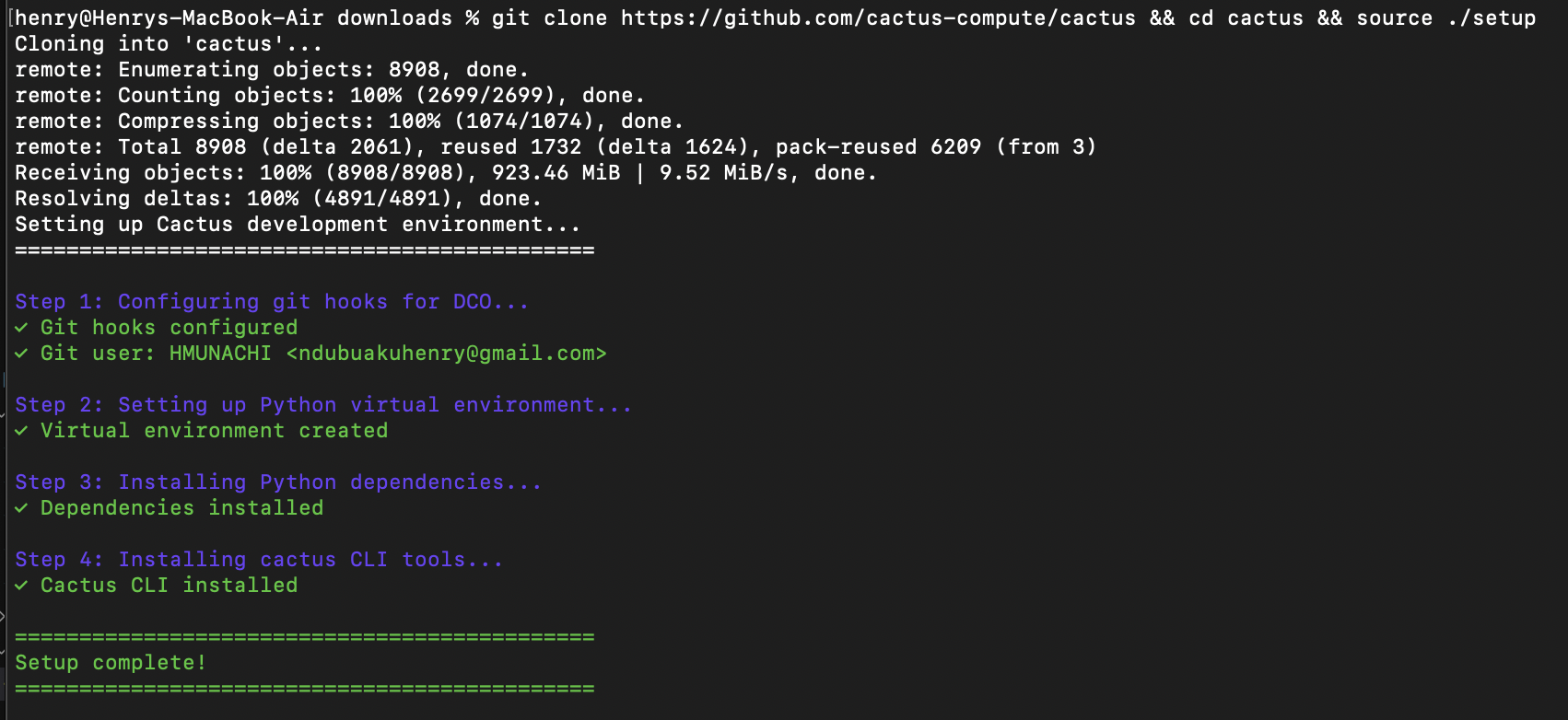
3. Für Cactus konvertieren

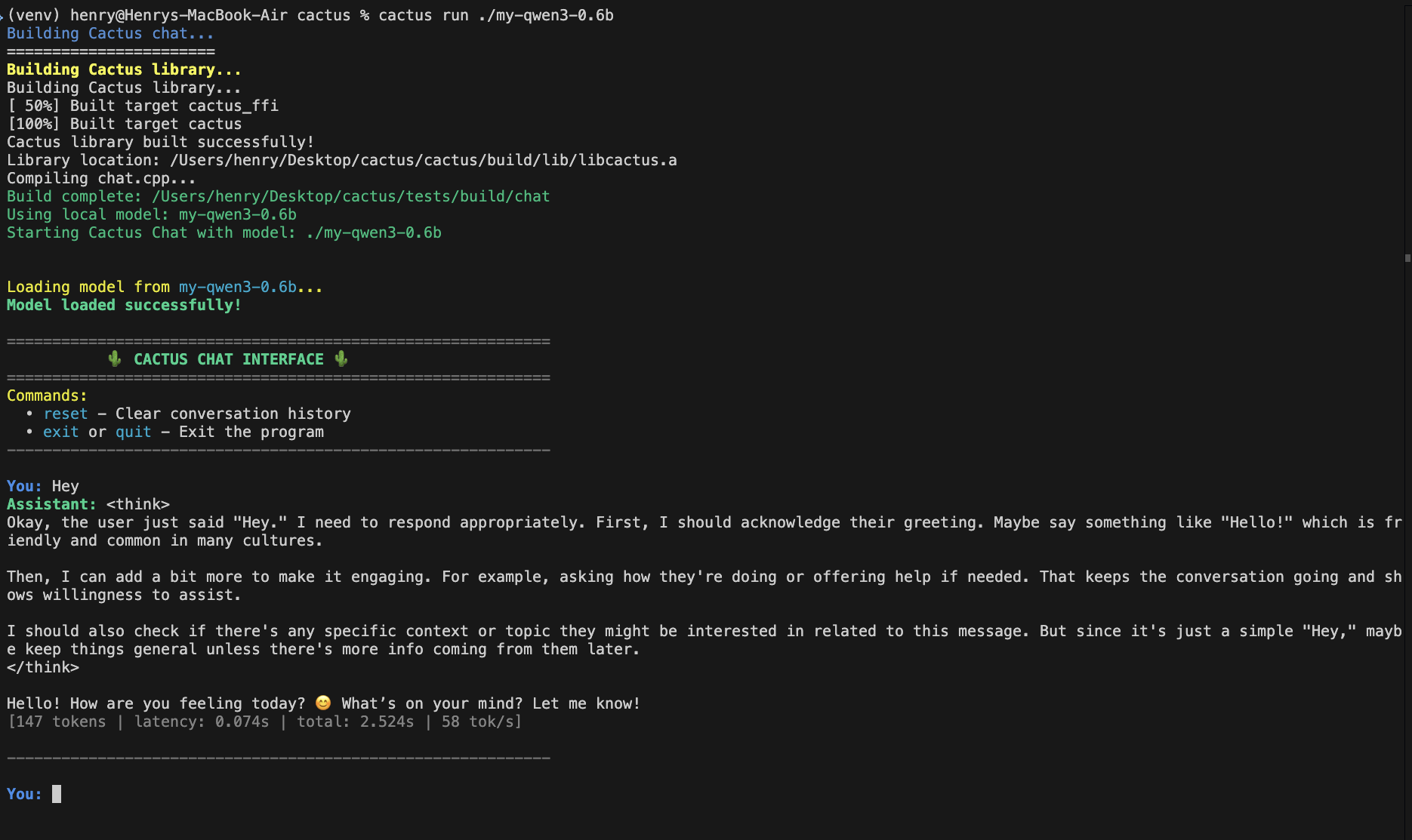
4. Ausführen
Testen Sie Ihr Modell auf dem Mac:
5. In iOS/macOS App verwenden
Bauen Sie die native Bibliothek:
Link cactus-ios.xcframework zu Ihrem Xcode-Projekt, dann:
Sie können jetzt iOS-Apps mit dem folgenden Code erstellen, aber um die Leistung auf einem Gerät während des Testens zu sehen, führen Sie cactus tests aus, indem Sie ein beliebiges iPhone an Ihren Mac anschließen und dann ausführen:
Cactus-Demo-Apps werden schließlich erweitert, um Ihre benutzerdefinierten Feineinstellungen zu verwenden. Außerdem cactus run ermöglicht das Anschließen eines Telefons, sodass die interaktive Sitzung die Chips des Telefons verwendet; auf diese Weise können Sie testen, bevor Sie Ihre Apps vollständig erstellen.
6. Verwendung in einer Android-App
Bauen Sie die native Bibliothek:
Kopieren libcactus.so zu app/src/main/jniLibs/arm64-v8a/, dann:
Sie können jetzt Android-Apps mit dem folgenden Code erstellen, aber um die Leistung auf einem Gerät während des Testens zu sehen, führen Sie cactus tests aus, indem Sie ein beliebiges Android-Telefon an Ihren Mac anschließen und dann ausführen:
Cactus-Demo-Apps werden schließlich erweitert, um Ihre benutzerdefinierten Feineinstellungen zu verwenden. Außerdem cactus run ermöglicht das Anschließen eines Telefons, sodass die interaktive Sitzung die Chips des Telefons verwendet; auf diese Weise können Sie testen, bevor Sie Ihre Apps vollständig erstellen.
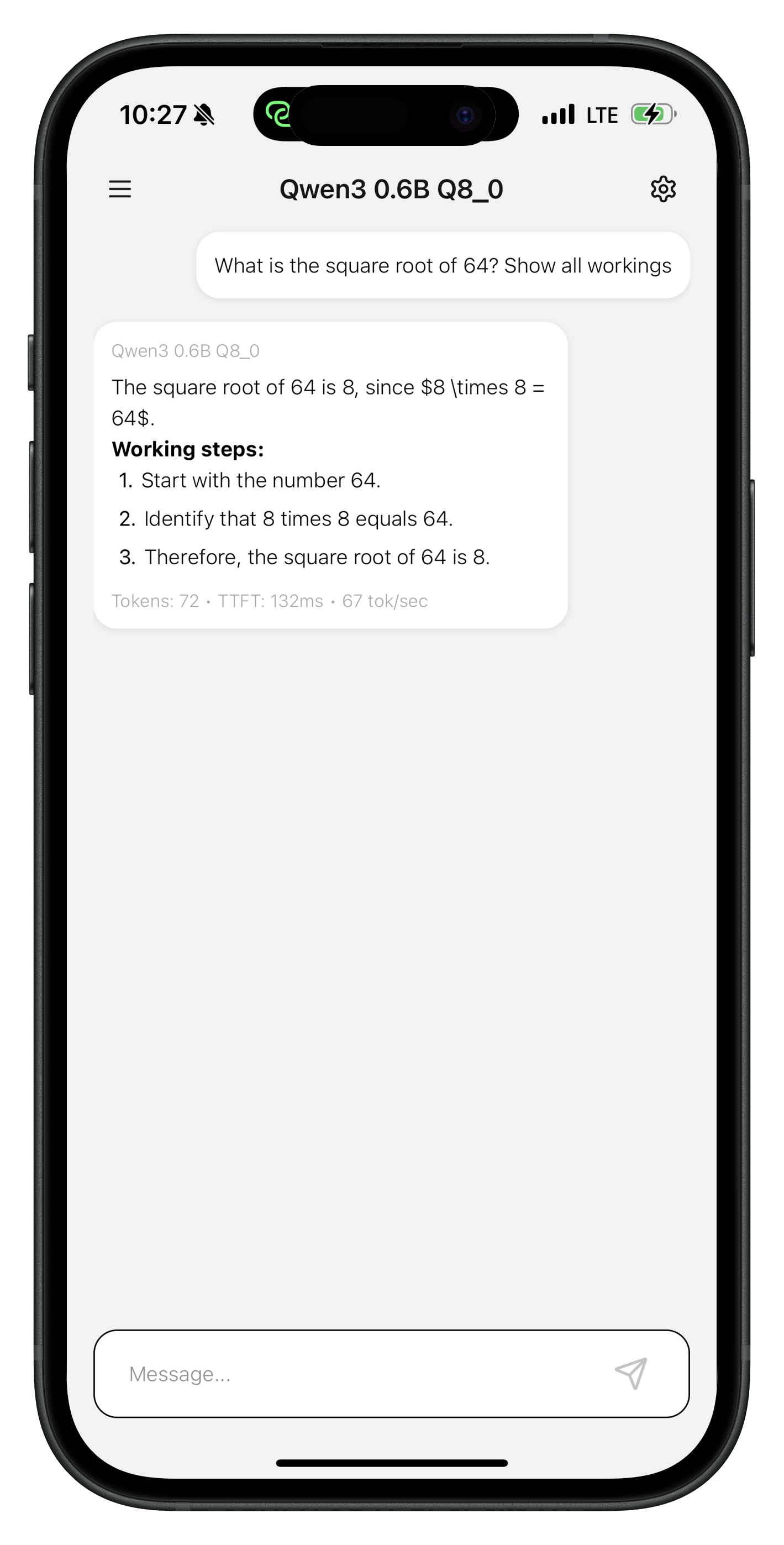
Ressourcen
Unterstützte Basismodelle:
Qwen3, Gemma3, LFM2, SmolLM2Vollständige API-Referenz: Cactus Engine
Erfahren Sie mehr und melden Sie Fehler: Cactus
Zuletzt aktualisiert
War das hilfreich?