

💧Liquid LFM2.5:実行&ファインチューニング方法
LFM2.5 Instruct と Vision を自分のデバイスでローカルに実行およびファインチューニングしましょう!
ダイナミックGGUF
16ビット指示(Instruct)
⚙️ 使用ガイド
チャットテンプレート形式
ツール使用
🖥️ LFM2.5-1.2B-Instructを実行する
📖 llama.cpp チュートリアル(GGUF)
🦥 UnslothでLFM2.5をファインチューニングする
LFM2.5用Unsloth設定
トレーニング設定
保存とエクスポート
🎉 llama-server サービング & デプロイメント
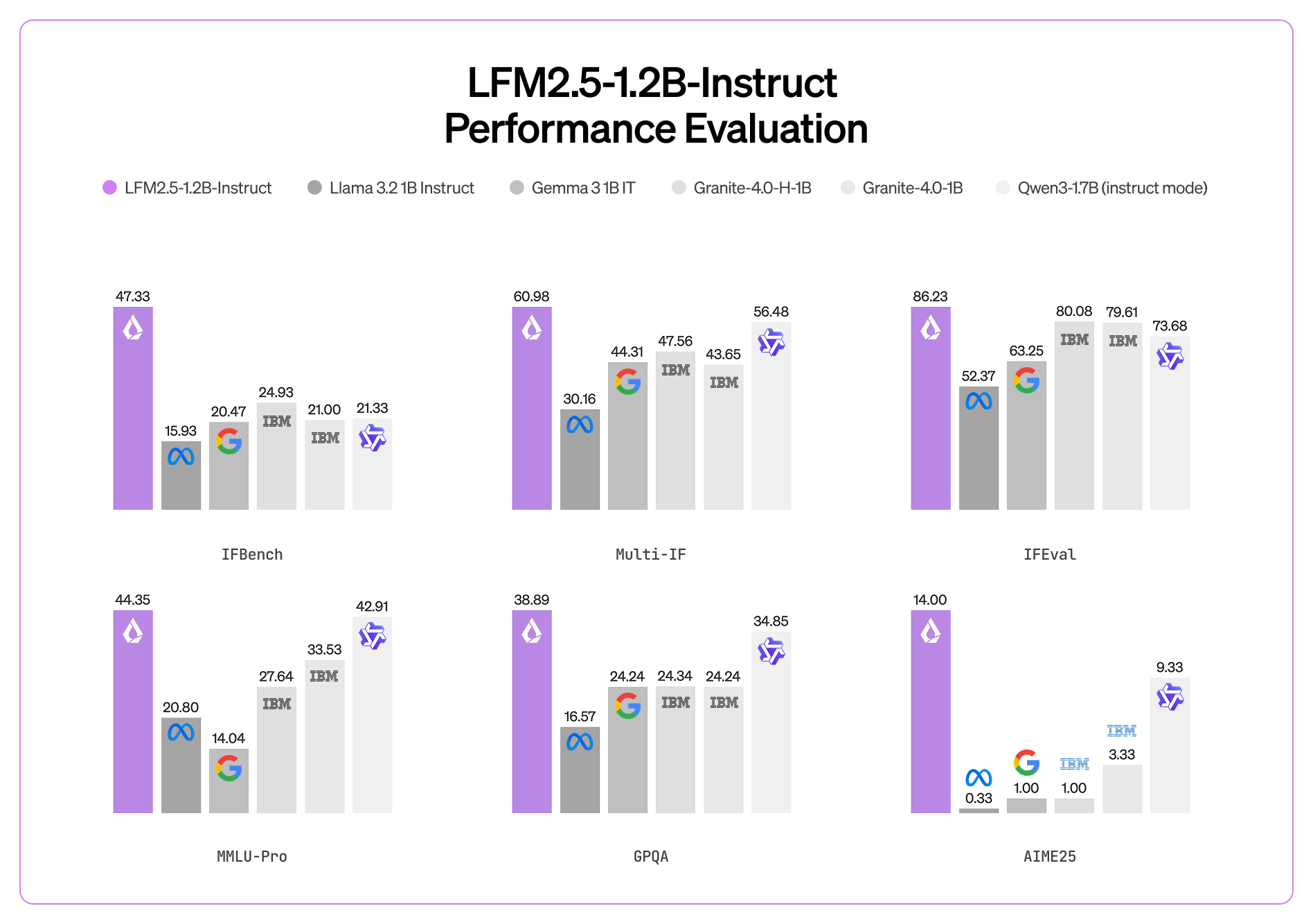
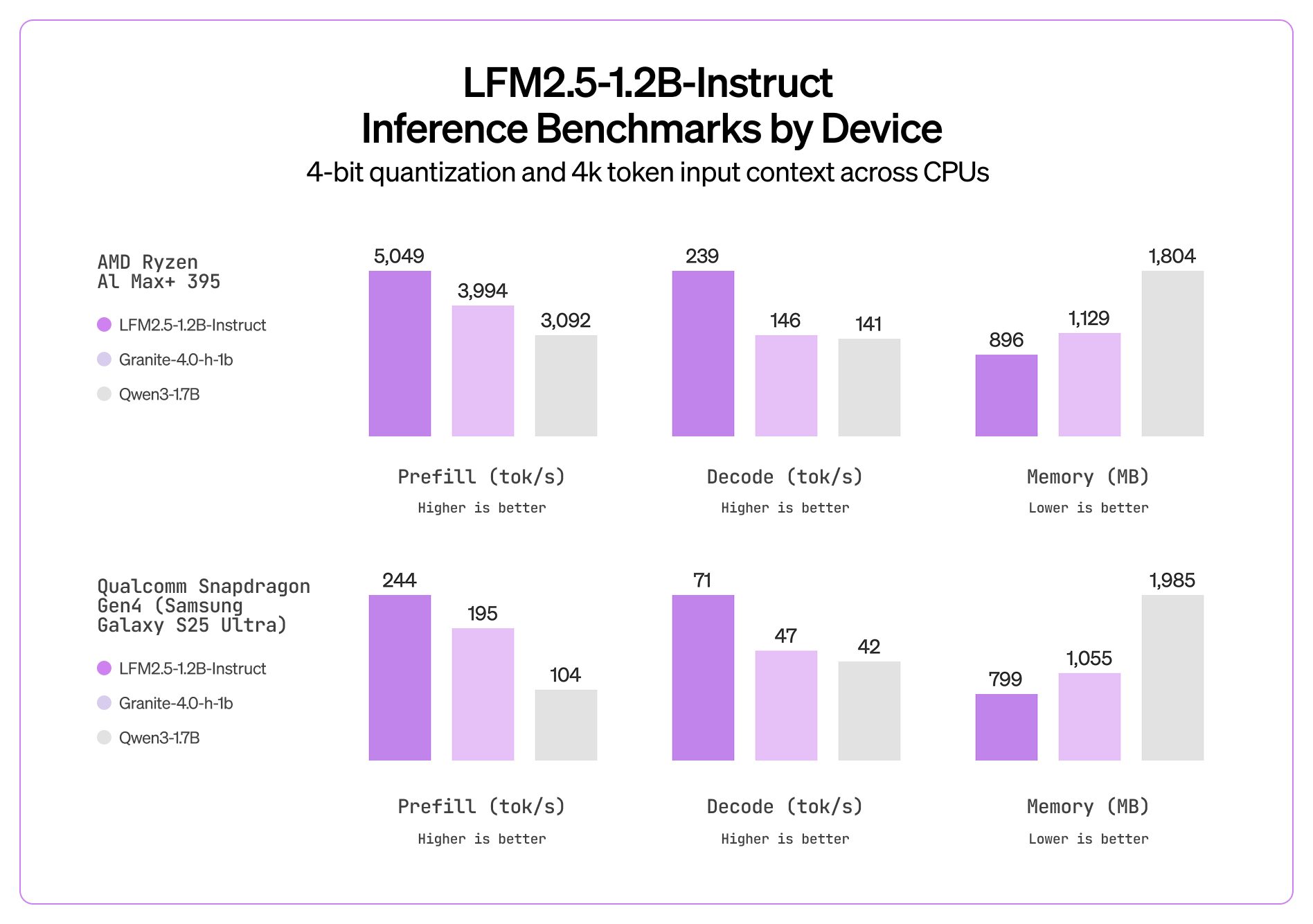
📊 ベンチマーク
💧 Liquid LFM2.5-1.2B-VL ガイド
ダイナミックGGUF
16ビット指示(Instruct)
⚙️ 使用ガイド
チャットテンプレート形式
🖥️ LFM2.5-VL-1.6Bを実行する
📖 llama.cpp チュートリアル(GGUF)
🦥 UnslothでLFM2.5-VLをファインチューニングする
LFM2.5用Unsloth設定
トレーニング設定
保存とエクスポート
📊 ベンチマーク
モデル
MMStar
MM-IFEval
BLINK
InfoVQA(検証)
OCRBench(v2)
RealWorldQA
MMMU(検証)
MMMB(平均)
多言語 MMBench(平均)
📚 リソース
最終更新
役に立ちましたか?