

📱iOS または Android 携帯で LLM を実行・デプロイする方法
独自の LLM をファインチューニングして ExecuTorch を使って Android や iPhone にデプロイするチュートリアル。


🦥 モデルのトレーニング
🏁 トレーニング後のデプロイ
iOS デプロイ
macOS 開発環境のセットアップ

Apple デベロッパーアカウントの設定

Apple Developer Program に登録する
ExecuTorch デモアプリのセットアップ

シミュレータへのデプロイ



物理 iPhone へのデプロイ





Android デプロイ
必要条件
確認
ステップ 1: Android SDK と NDK のインストール
ステップ 2: 環境変数を設定
source ~/.zshrc # またはシェルに応じて ~/.bashrc
export ANDROID_NDK=$ANDROID_HOME/ndk/25.0.8775105
cd executorch-examples
sed -i 's/e.getDetailedError()/e.getMessage()/g' llm/android/LlamaDemo/app/src/main/java/com/example/executorchllamademo/MainActivity.java
app/build/outputs/apk/debug/app-debug.apk
アプリをインストールする方法は 2 つあります。
adb install -r app/build/outputs/apk/debug/app-debug.apk
タップしてインストール(促されたら「提供元不明のアプリのインストールを許可」を有効に)
トラブルシューティング
ファイルは通常 CPU 用の XNNPACK バックエンドなど、ExecuTorch 用に特別にエクスポートされている必要があります。
我々がビルドしたアプリは Android 上で特定のディレクトリからのみモデルをロードすることをサポートしており、そのディレクトリは通常のファイルマネージャからはアクセスできません。しかし adb を使えばそのディレクトリにモデルファイルを保存できます。












📱「successfully loaded model」と表示されたら、モデルとチャットを開始できます。
さあ、これで Android 電話上でネイティブに LLM が動作しています!
Meta の Quest 3 や Ray-Ban
ページにあります!
を Raspberry Pi で達成します。
クイックスタート
model.push_to_hub("username/my-lora-adapter")
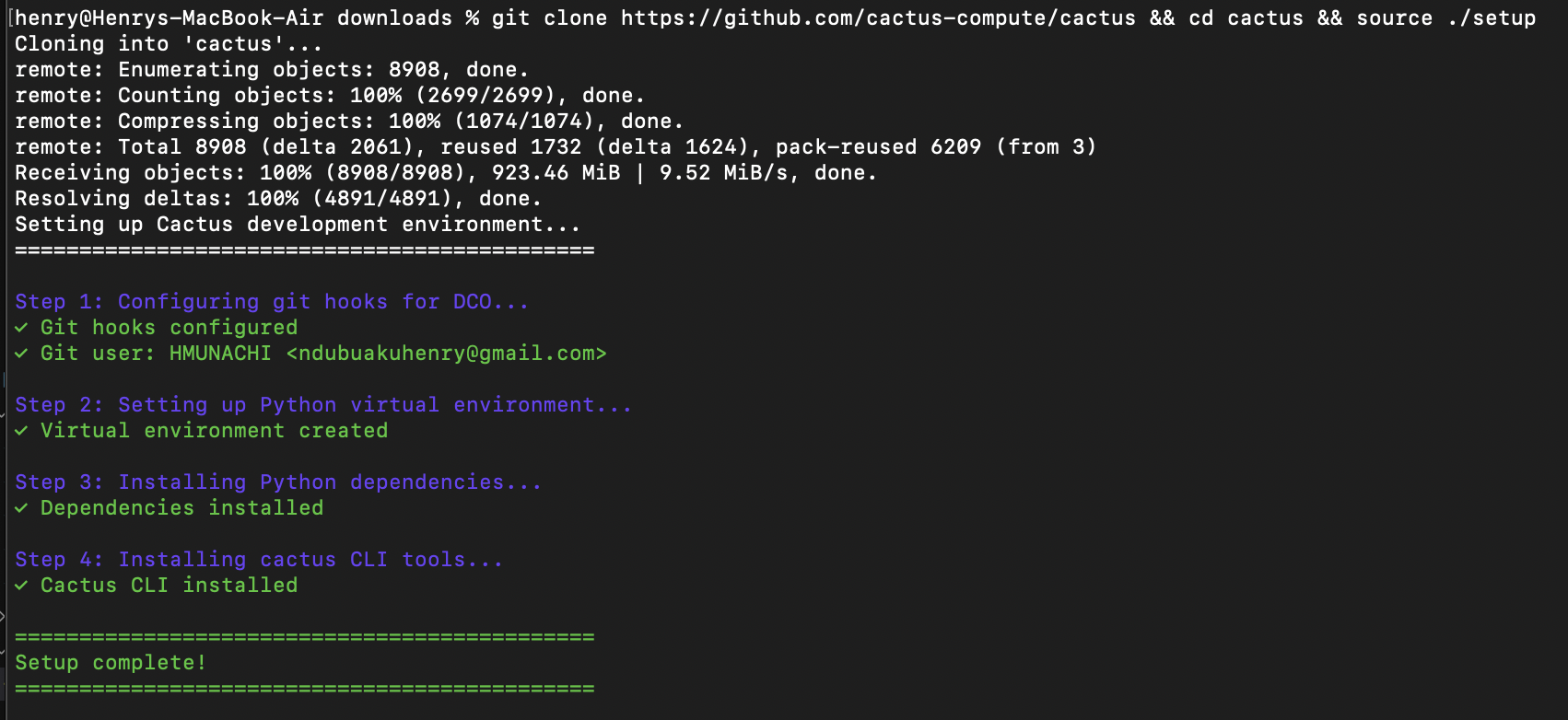
git clone https://github.com/cactus-compute/cactus && cd cactus && source ./setup

cactus convert Qwen/Qwen3-0.6B ./my-qwen3-0.6b --lora username/my-lora-adapter
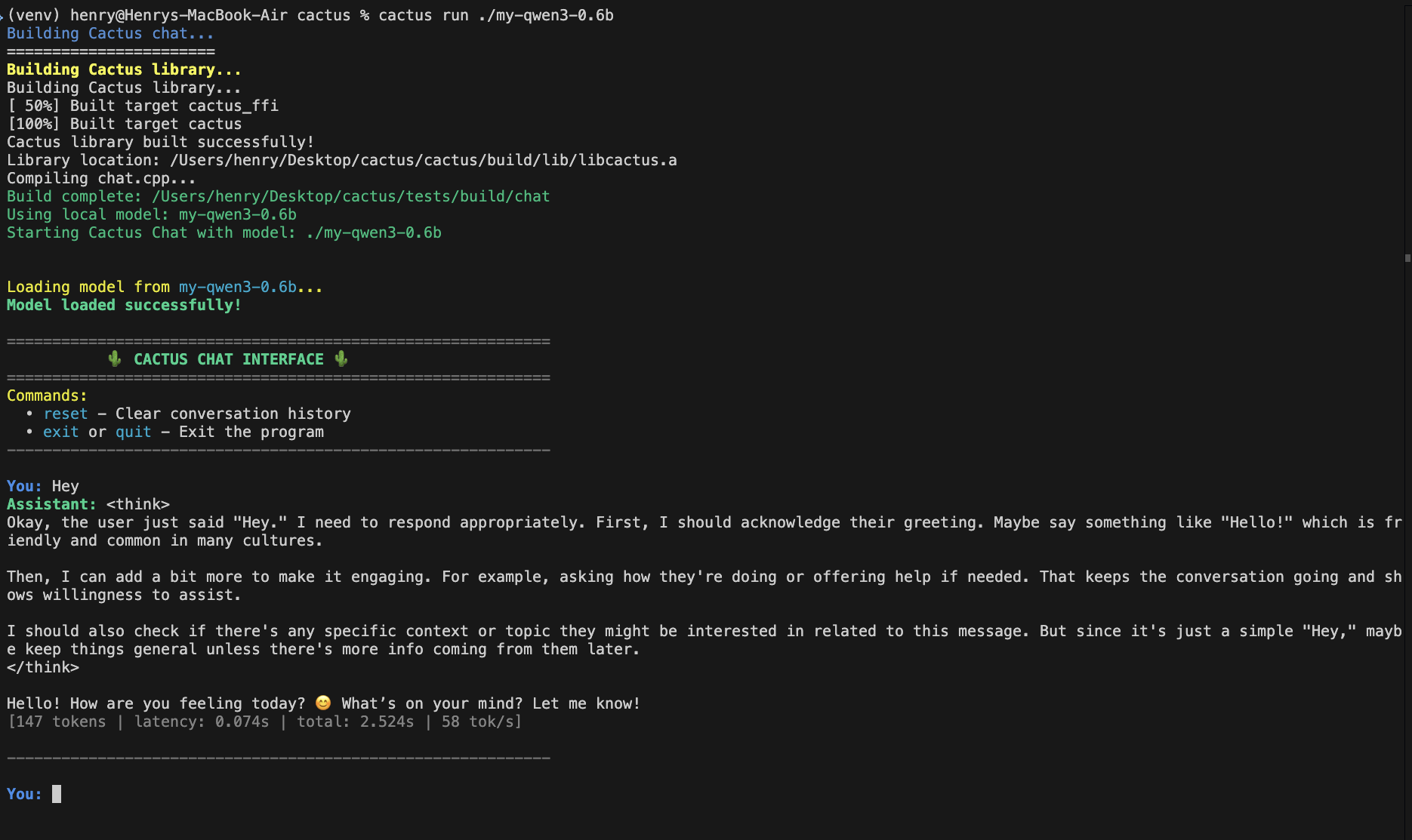
cactus run ./my-qwen3-0.6b
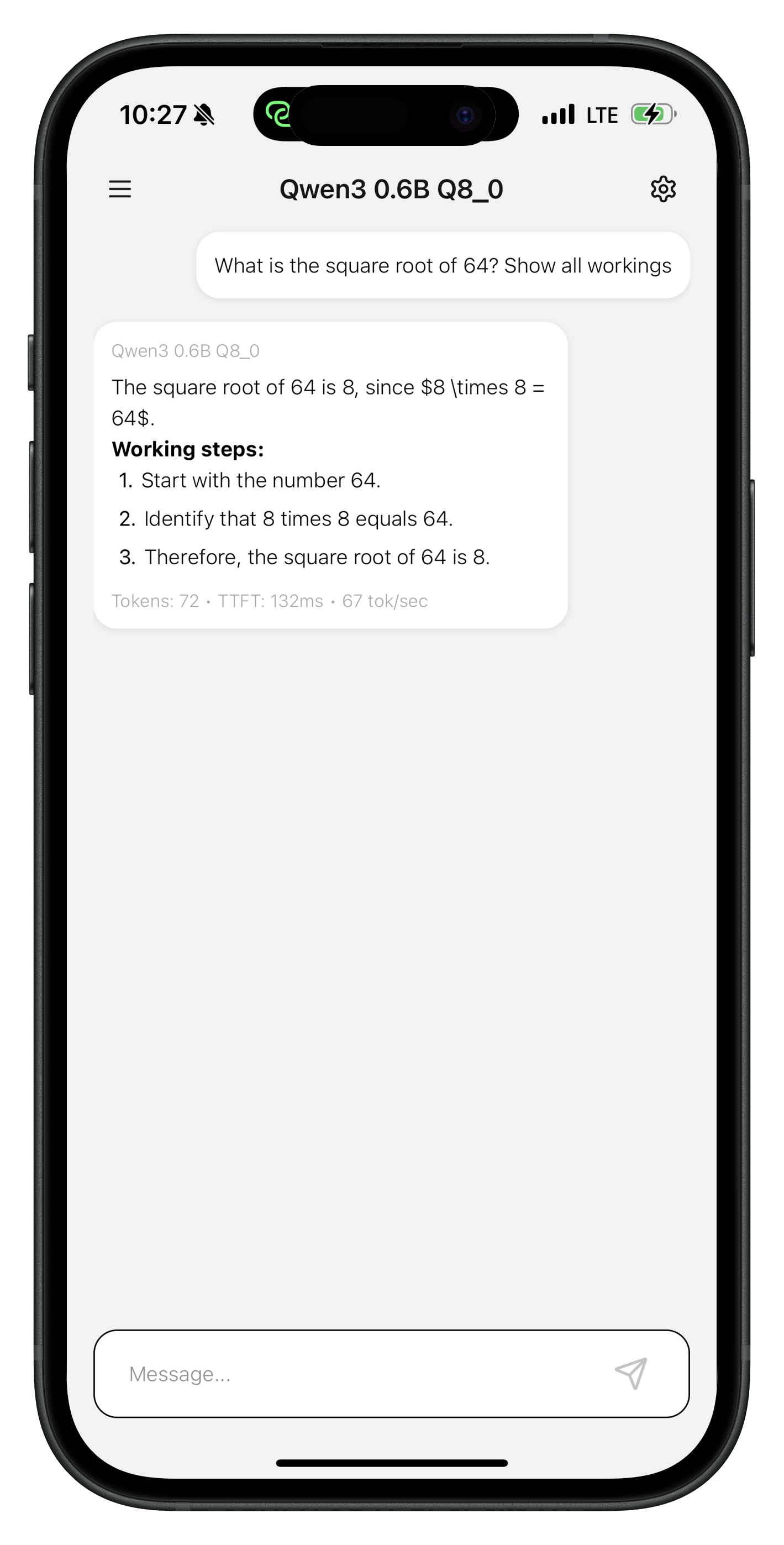
6. Androidアプリでの使用
リソース
最終更新
役に立ちましたか?