

💧Liquid LFM2.5 : Comment exécuter & affiner
Exécutez et affinez LFM2.5 Instruct et Vision localement sur votre appareil !
GGUF dynamiques
Instruct 16-bit
⚙️ Guide d'utilisation
Format du modèle de conversation
Utilisation d'outils
🖥️ Exécuter LFM2.5-1.2B-Instruct
📖 Tutoriel llama.cpp (GGUF)
🦥 Fine-tuning de LFM2.5 avec Unsloth
Configuration Unsloth pour LFM2.5
Configuration d'entraînement
Enregistrer et exporter
🎉 Serving & déploiement llama-server
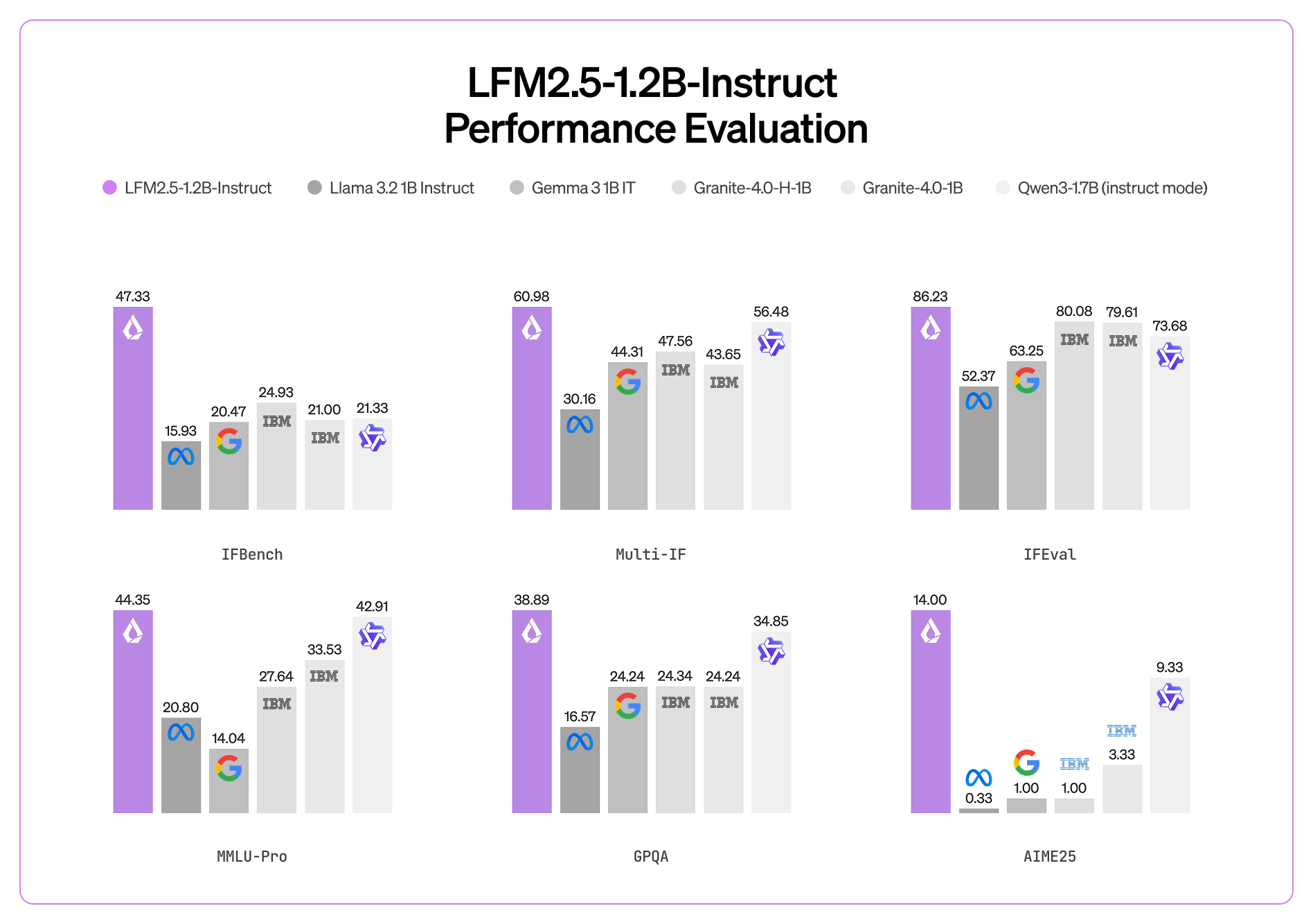
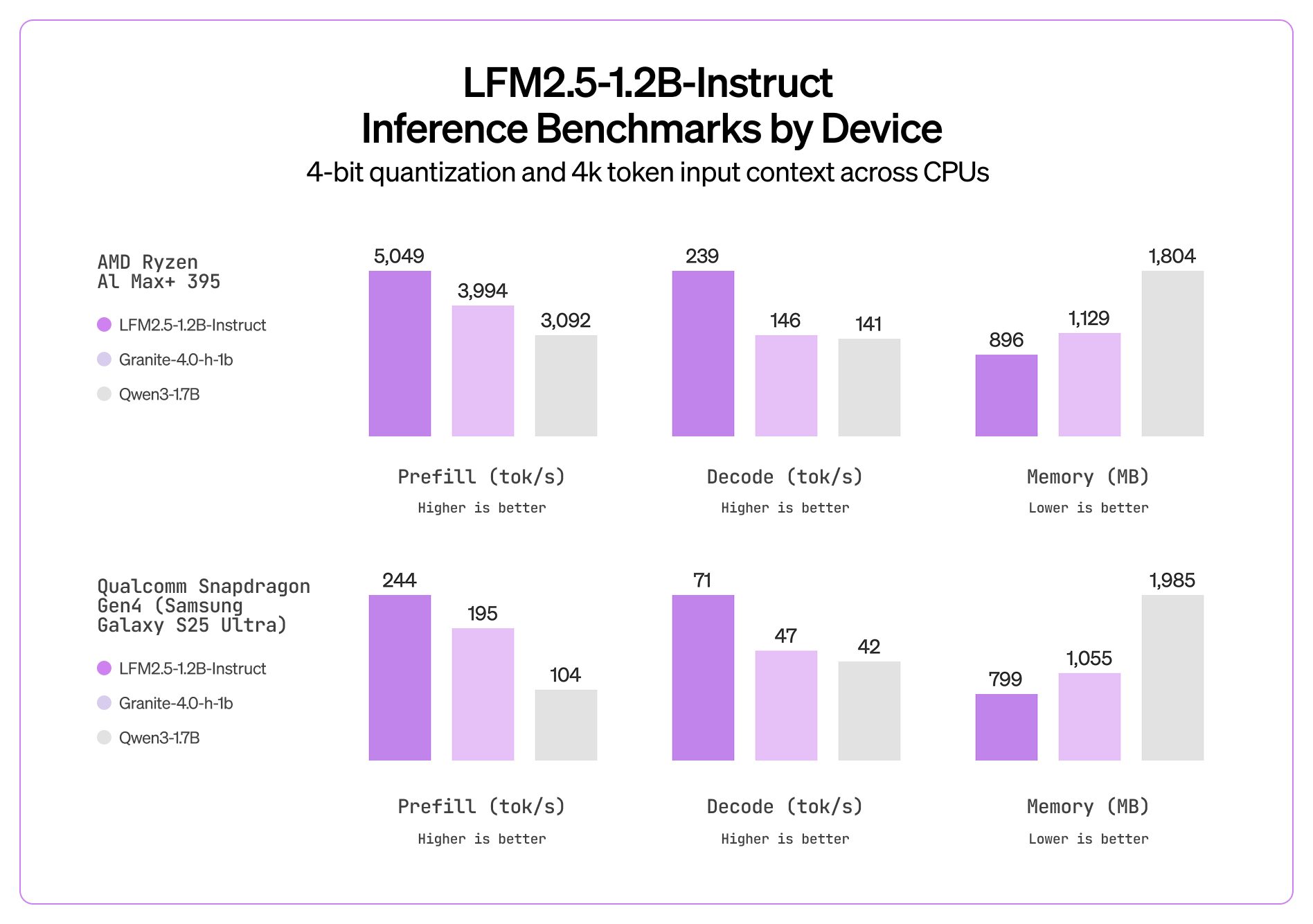
📊 Benchmarks
💧 Guide Liquid LFM2.5-1.2B-VL
GGUF dynamiques
Instruct 16-bit
⚙️ Guide d'utilisation
Format du modèle de conversation
🖥️ Exécuter LFM2.5-VL-1.6B
📖 Tutoriel llama.cpp (GGUF)
🦥 Fine-tuning de LFM2.5-VL avec Unsloth
Configuration Unsloth pour LFM2.5
Configuration d'entraînement
Enregistrer et exporter
📊 Benchmarks
Modèle
MMStar
MM-IFEval
BLINK
InfoVQA (Val)
OCRBench (v2)
RealWorldQA
MMMU (Val)
MMMB (moyenne)
Multilingual MMBench (moyenne)
📚 Ressources
Mis à jour
Ce contenu vous a-t-il été utile ?