

📱Comment exécuter et déployer des LLM sur votre téléphone iOS ou Android
Tutoriel pour affiner votre propre LLM et le déployer sur votre appareil Android ou iPhone avec ExecuTorch.
Nous sommes ravis de montrer comment vous pouvez entraîner des LLM puis les déployer localement en Téléphones Android et iPhones. Nous avons collaboré avec ExecuTorch de PyTorch & Meta pour créer un flux de travail simplifié utilisant l'entraînement conscient de la quantification (QAT) puis les déployer directement sur des appareils périphériques. Avec Unsloth, TorchAO et ExecuTorch, nous montrons comment vous pouvez :
Utiliser la même technologie (ExecuTorch) que Meta utilise pour alimenter des milliards d'utilisateurs sur Instagram, WhatsApp
Déployer Qwen3-0.6B localement sur Pixel 8 et iPhone 15 Pro à ~40 tokens/s
Appliquer le QAT via TorchAO pour récupérer 70 % de l'exactitude
Obtenir la confidentialité d'abord, des réponses instantanées et des capacités hors ligne
Utilisez notre notebook Colab gratuit pour affiner Qwen3 0.6B et l'exporter pour le déploiement sur téléphone
Qwen3-4B déployé sur un iPhone 15 Pro

Qwen3-0.6B fonctionnant à ~40 tokens/s

🦥 Entraîner votre modèle
Nous prenons en charge Qwen3, Gemma3, Llama3, Qwen2.5, Phi4 et de nombreux autres modèles pour le déploiement sur téléphone ! Suivez le notebook Colab gratuit pour le déploiement de Qwen3-0.6B :
Mettez d'abord à jour Unsloth et installez TorchAO et Executorch.
Ensuite, utilisez simplement qat_scheme = "phone-deployment" pour signifier que nous voulons le déployer sur un téléphone. Notez que nous définissons aussi full_finetuning = True pour un affinage complet !
Nous utilisons qat_scheme = "phone-deployment" nous utilisons en fait qat_scheme = "int8-int4" en coulisses pour activer le QAT Unsloth/TorchAO qui simule la quantification dynamique d'activation INT8 avec quantification des poids INT4 pour les couches Linear pendant l'entraînement (via des opérations de fausse quantification) tout en gardant les calculs en 16 bits. Après l'entraînement, le modèle est converti en une version réellement quantifiée afin que le modèle sur l'appareil soit plus petit et typiquement conserve mieux la précision que la PTQ naïve.
Après l'affinage tel que décrit dans le notebook Colab, nous l'enregistrons ensuite dans un .pte fichier via Executorch :
🏁 Déploiement après l'entraînement
Et maintenant, avec votre qwen3_0.6B_model.pte fichier qui pèse environ 472 Mo, nous pouvons le déployer ! Choisissez votre appareil et lancez-vous :
Run LLMs on your Phone – Route Xcode, simulateur ou appareil
Run LLMs on your Phone – route en ligne de commande, aucun Studio requis
Déploiement iOS
Tutoriel pour faire fonctionner votre modèle sur iOS (testé sur un iPhone 16 Pro mais fonctionnera également sur d'autres iPhones). Vous aurez besoin d'un appareil physique basé sur macOS capable d'exécuter XCode 15.
Configuration de l'environnement de développement macOS
Installer Xcode et les outils en ligne de commande
Installez Xcode depuis le Mac App Store (doit être la version 15 ou ultérieure)
Ouvrez Terminal et vérifiez votre installation :
xcode-select -pInstallez les outils en ligne de commande et acceptez la licence :
xcode-select --installsudo xcodebuild -license accept
Lancez Xcode pour la première fois et installez tous les composants supplémentaires lorsqu'on vous le demande
Si on vous demande de sélectionner des plateformes, choisissez iOS 18 et téléchargez-le pour l'accès au simulateur
Vérifiez que tout fonctionne : xcode-select -p
Vous devriez voir un chemin affiché. Sinon, répétez l'étape 3.

Configuration du compte Apple Developer
Pour les appareils physiques uniquement !
Ignorez toute cette section si vous utilisez uniquement le simulateur iOS. Vous n'avez besoin d'un compte développeur payant que pour le déploiement sur un iPhone physique.
Créez votre identifiant Apple
Vous n'avez pas d'identifiant Apple ? Inscrivez-vous ici.
Ajoutez votre compte à Xcode
Ouvrez Xcode
Allez dans Xcode → Réglages → Comptes
Cliquez sur le bouton + et sélectionnez Identifiant Apple
Connectez-vous avec votre identifiant Apple habituel

Inscrivez-vous au programme Apple Developer
ExecuTorch requiert la capacité increased-memory-limit, qui nécessite un compte développeur payant :
Visitez developer.apple.com
Connectez-vous avec votre identifiant Apple
Inscrivez-vous au programme Apple Developer
Configurer l'application démo ExecuTorch
Récupérez le code d'exemple :
Ouvrir dans Xcode
Ouvrir
apple/etLLM.xcodeprojdans XcodeDans la barre d'outils supérieure, sélectionnez
iPhone 16 ProSimulateur comme appareil cibleAppuyez sur Play (▶️) pour compiler et exécuter
🎉 Succès ! L'application devrait maintenant se lancer dans le simulateur. Elle ne fonctionnera pas encore, nous devons ajouter votre modèle.

Déploiement sur le simulateur
Aucun compte développeur n'est nécessaire.
Préparez vos fichiers de modèle
Arrêtez le simulateur dans Xcode (appuyez sur le bouton stop)
Accédez à votre dépôt HuggingFace Hub (si non enregistré localement)
Téléchargez ces deux fichiers :
qwen3_0.6B_model.pte(votre modèle exporté)tokenizer.json (le tokenizer)
Créez un dossier partagé sur le simulateur
Cliquez sur le bouton Accueil virtuel du simulateur
Ouvrez l'application Fichiers → Parcourir → Sur mon iPhone
Appuyez sur le bouton ellipsis (•••) et créez un nouveau dossier nommé
Qwen3test
Transférer des fichiers en utilisant le Terminal
Lorsque vous voyez le dossier, exécutez ce qui suit :
Charger et discuter
Retournez à l'application etLLM dans le simulateur. Appuyez dessus pour la lancer.

Chargez le modèle et le tokenizer depuis le dossier Qwen3test

Commencez à discuter avec votre modèle affiné ! 🎉

Déploiement sur votre iPhone physique
Configuration initiale de l'appareil
Connectez votre iPhone à votre Mac via USB
Déverrouillez votre iPhone et appuyez sur « Se fier à cet appareil »
Dans Xcode, allez à Fenêtre → Appareils et Simulateurs
Attendez que votre appareil apparaisse à gauche (il peut afficher « Préparation » pendant un moment)
Configurer la signature Xcode
Ajoutez votre compte Apple : Xcode → Réglages → Comptes →
+Dans le navigateur de projet, cliquez sur le projet etLLM (icône bleue)
Sélectionnez etLLM sous TARGETS
Allez à l'onglet Signing & Capabilities
Cochez « Gérer automatiquement la signature »
Sélectionnez votre équipe dans le menu déroulant

Changez l'identifiant de bundle pour quelque chose d'unique (par ex., com.votrenom.etLLM). Cela corrige 99 % des erreurs de profil de provisioning
Ajouter la capacité requise
Toujours dans Signing & Capabilities, cliquez sur + Capability
Recherchez « Increased Memory Limit » et ajoutez-la
Compiler et exécuter
Dans la barre d'outils supérieure, sélectionnez votre iPhone physique dans le sélecteur d'appareils
Appuyez sur Play (▶️) ou pressez Cmd + R
Faire confiance au certificat développeur
Votre première compilation échouera — c'est normal !
Sur votre iPhone, allez dans Réglages → Confidentialité & Sécurité → Mode Développeur
Activez l'option
Acceptez et validez les avis
Redémarrez l'appareil, retournez à Xcode et appuyez de nouveau sur Play
Le Mode Développeur permet à XCode d'exécuter et d'installer des applications sur votre iPhone
Transférer les fichiers du modèle vers votre iPhone

Une fois l'application en cours d'exécution, ouvrez Finder sur votre Mac
Sélectionnez votre iPhone dans la barre latérale
Cliquez sur l'onglet Fichiers
Développez etLLM
Glissez-déposez vos fichiers .pte et tokenizer.json directement dans ce dossier
Soyez patient ! Ces fichiers sont volumineux et peuvent prendre quelques minutes
Charger et discuter
Sur votre iPhone, revenez à l'application etLLM

Chargez le modèle et le tokenizer depuis l'interface de l'application

Votre Qwen3 affiné fonctionne maintenant nativement sur votre iPhone !

Déploiement Android
Ce guide couvre comment construire et installer l'application démo ExecuTorch Llama sur un appareil Android (testé avec Pixel 8 mais fonctionnera aussi sur d'autres téléphones Android) en utilisant un environnement en ligne de commande Linux/Mac. Cette approche minimise les dépendances (pas besoin d'Android Studio) et déleste le processus de build intensif sur votre ordinateur.
Exigences
Assurez-vous que votre machine de développement ait les éléments suivants installés :
Java 17 (Java 21 est souvent par défaut mais peut causer des problèmes de build)
Git
Wget / Curl
Outils en ligne de commande Android
Guide d'installation et configuration
adbsur votre Android et votre ordinateur
Vérification
Vérifiez que votre version de Java correspond à 17.x :
Si ce n'est pas le cas, installez-le via Ubuntu/Debian :
Puis définissez-le par défaut ou exportez JAVA_HOME:
Si vous êtes sur un autre OS ou distribution, vous pouvez suivre ce guide ou simplement demander à votre LLM préféré de vous guider.
Étape 1 : Installer Android SDK & NDK
Configurez un environnement SDK Android minimal sans l'intégralité d'Android Studio.
1. Créez le répertoire SDK :
Installer les outils en ligne de commande Android
Étape 2 : Configurer les variables d'environnement
Ajoutez-les à votre ~/.bashrc ou ~/.zshrc:
Rechargez-les :
Étape 3 : Installer les composants SDK
ExecuTorch nécessite des versions spécifiques du NDK.
Définir la variable NDK :
Étape 4 : Récupérer le code
Nous utilisons le executorch-examples dépôt, qui contient la démo Llama mise à jour.
Étape 5 : Corriger les problèmes de compilation courants
Notez que le code actuel n'a pas ces problèmes mais nous les avons rencontrés auparavant et cela pourrait vous être utile :
Corriger « SDK Location not found » :
Créez un local.properties fichier pour indiquer explicitement à Gradle où se trouve le SDK :
Corriger cannot find symbol erreur :
Le code actuel utilise une méthode obsolète getDetailedError(). Appliquez ce correctif avec cette commande :
Étape 6 : Construire l'APK
Cette étape compile l'application et les bibliothèques natives.
Accédez au projet Android :
Construire avec Gradle (définir explicitement
JAVA_HOMEà 17 pour éviter les erreurs de toolchain) :Remarque : La première exécution prendra quelques minutes.
L'apk final généré se trouve à :
Étape 7 : Installer sur votre appareil Android
Vous avez deux options pour installer l'application.
Option A : Utiliser ADB (filiaire/sans fil)
Si vous avez adb accès à votre téléphone :
Option B : Transfert direct de fichier
Si vous êtes sur une VM distante ou n'avez pas de câble :
Téléversez l'app-debug.apk à un endroit où vous pouvez la télécharger sur le téléphone
Téléchargez-la sur votre téléphone
Appuyez pour installer (Activez « Installer des sources inconnues » si demandé).
Étape 8 : Transférer les fichiers du modèle
L'application a besoin des fichiers modèle .pte et tokenizer.
Transférer les fichiers : Déplacez votre model.pte et tokenizer.bin (ou tokenizer.model) vers le stockage de votre téléphone (par ex., dossier Téléchargements).
Ouvrir l'application LlamaDemo : Lancez l'application sur votre téléphone.
Sélectionner le modèle
Appuyez sur Paramètres (icône d'engrenage) ou le sélecteur de fichiers.
Accédez à votre dossier Téléchargements.
Sélectionnez votre fichier .pte.
Sélectionnez votre fichier tokenizer.
Terminé ! Vous pouvez maintenant discuter avec le LLM directement sur votre appareil.
Dépannage
Échec de la compilation ? Vérifiez java -version. Il DOIT être 17.
Le modèle ne se charge pas ? Assurez-vous d'avoir sélectionné à la fois le
.pteET letokenizer.L'application plante ? Les
.ptefichiers valides doivent être exportés spécifiquement pour ExecuTorch (généralement backend XNNPACK pour le CPU).
Transférer le modèle vers votre téléphone
Actuellement, executorchllama l'application que nous avons construite ne supporte le chargement du modèle que depuis un répertoire spécifique sur Android qui n'est malheureusement pas accessible via les gestionnaires de fichiers habituels. Mais nous pouvons enregistrer les fichiers du modèle dans ce répertoire à l'aide d'adb.
Assurez-vous qu'adb fonctionne correctement et est connecté
Si vous vous êtes connecté via le débogage sans fil, vous verrez quelque chose comme ceci :

Ou si vous vous êtes connecté via un câble :

Si vous n'avez pas donné les permissions à l'ordinateur pour accéder à votre téléphone :

Alors vous devez vérifier votre téléphone pour un dialogue contextuel qui ressemble à (que vous voudrez peut-être autoriser)

Une fois fait, il est temps de créer le dossier où nous devons placer les .pte et tokenizer.json fichiers.
Créez le répertoire indiqué sur le chemin du téléphone.
Vérifiez que le répertoire est correctement créé.
Poussez le contenu vers le répertoire indiqué. Cela peut prendre de quelques minutes à plus selon votre ordinateur, la connexion et le téléphone. Veuillez être patient.

Ouvrez l'
executorchllamademoapplication que vous avez installée à l'étape 5, puis appuyez sur l'icône d'engrenage en haut à droite pour ouvrir les Paramètres.Appuyez sur la flèche à côté de Model pour ouvrir le sélecteur et sélectionnez un modèle. Si vous voyez une boîte blanche vide sans nom de fichier, votre push ADB du modèle a probablement échoué - refaites cette étape. Notez aussi qu'il peut afficher initialement « aucun modèle sélectionné ».
Après avoir sélectionné un modèle, l'application devrait afficher le nom du fichier du modèle.


Répétez maintenant la même opération pour le tokenizer. Cliquez sur la flèche à côté du champ tokenizer et sélectionnez le fichier correspondant.

Il se peut que vous deviez sélectionner le type de modèle en fonction du modèle que vous téléversez. Qwen3 est sélectionné ici.

Une fois que vous avez sélectionné les deux fichiers, cliquez sur le bouton « Load Model ».

Cela vous ramènera à l'écran d'origine avec la fenêtre de chat, et il se peut qu'il affiche « model loading ». Cela peut prendre quelques secondes pour terminer le chargement selon la RAM et la vitesse de stockage de votre téléphone.

Une fois qu'il indique « successfully loaded model », vous pouvez commencer à discuter avec le modèle. Et voilà, vous avez maintenant un LLM fonctionnant nativement sur votre téléphone Android !

📱ExecuTorch alimente des milliards
ExecuTorch alimente des expériences ML sur appareil pour des milliards de personnes sur Instagram, WhatsApp, Messenger et Facebook. Instagram Cutouts utilise ExecuTorch pour extraire des autocollants modifiables à partir de photos. Dans des applications chiffrées comme Messenger, ExecuTorch permet l'identification linguistique et la traduction respectueuses de la vie privée sur l'appareil. ExecuTorch prend en charge plus d'une douzaine de backends matériels sur Apple, Qualcomm, ARM et Quest 3 et Ray Bans de Meta.
Support d'autres modèles
Tous les modèles denses Qwen 3 (Qwen3-0.6B, Qwen3-4B, Qwen3-32B etc)
Tous les modèles Gemma 3 (Gemma3-270M, Gemma3-4B, Gemma3-27B etc)
Tous les modèles Llama 3 (Llama 3.1 8B, Llama 3.3 70B Instruct etc)
Qwen 2.5, Phi 4 Mini et bien d'autres !
Vous pouvez personnaliser le notebook Colab gratuit pour Qwen3-0.6B afin de permettre le déploiement sur téléphone pour n'importe lequel des modèles ci-dessus !
Notebook principal de déploiement sur téléphone pour Qwen3 0.6B
Fonctionne avec Gemma 3
Fonctionne avec Llama 3
Allez sur notre Notebooks Unsloth page pour tous les autres notebooks !
🌵 Déploiement vers Cactus pour téléphones
Cactus est un moteur d'inférence open-source pour appareils mobiles, Macs et puces ARM comme le Raspberry Pi.
En INT8, Cactus exécute
Qwen3-0.6BetLFM2-1.2Bà60-70 toks/secsur iPhone 17 Pro,13-18 toks/secsur un Pixel 6a économique.Accords INT8 spécifiques à la tâche de
Gemma3-270matteignent150 toks/secsur iPhone 17 Pro et23 toks/secsur Raspberry Pi.
Démarrage rapide
1. Entraîner (Google Colab / GPU)
Utilisez le notebook fourni ou votre propre script d'entraînement Unsloth :
2. Configurer Cactus
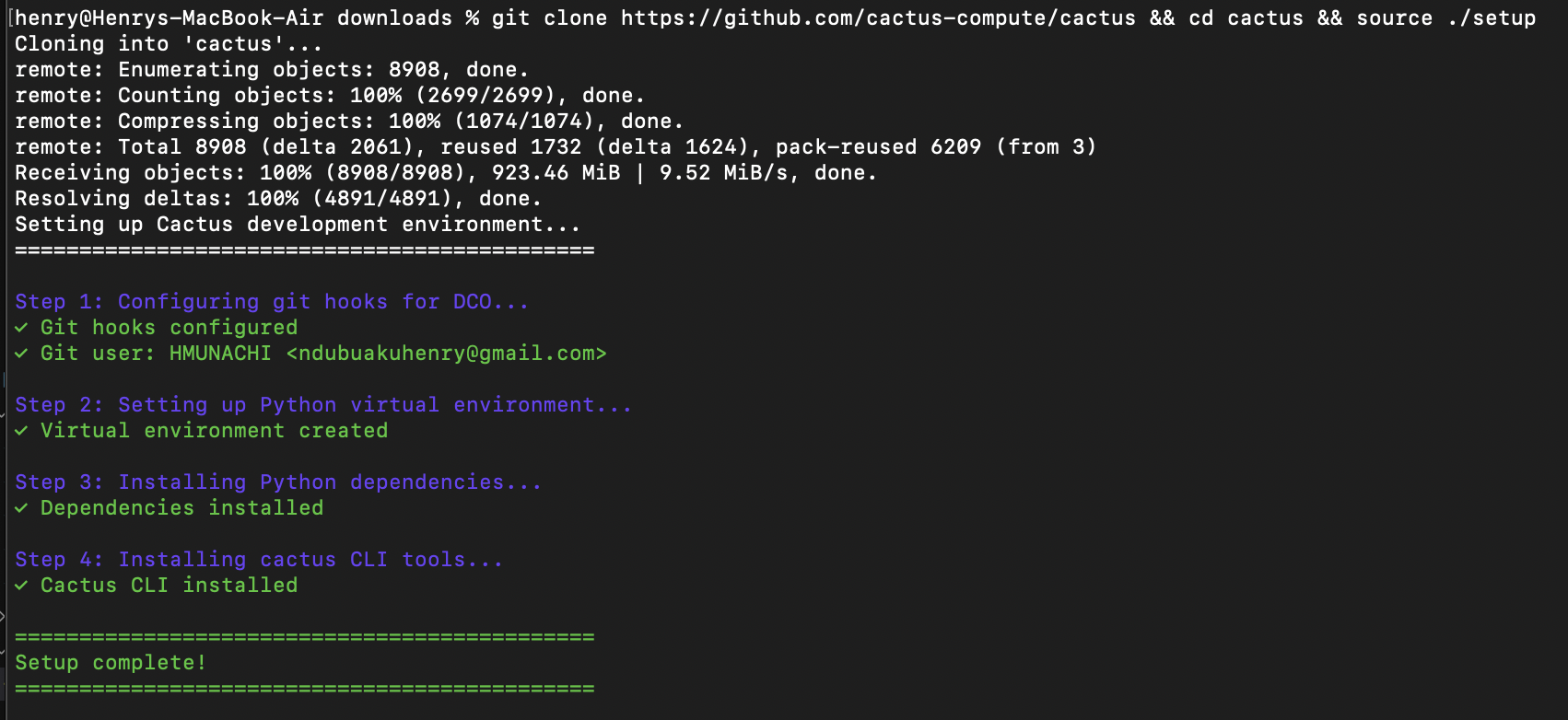
3. Convertir pour Cactus

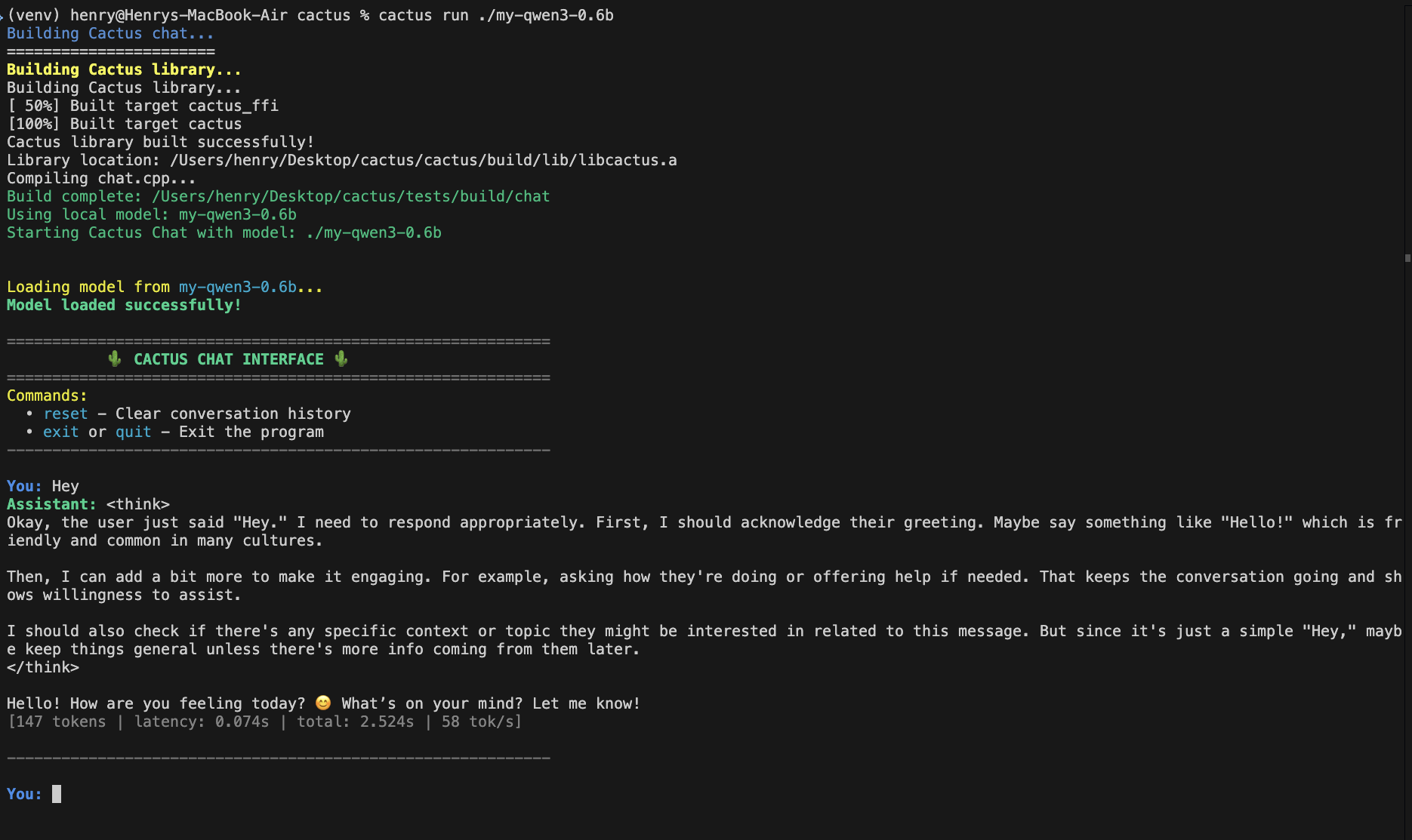
4. Exécuter
Testez votre modèle sur Mac :
5. Utiliser dans une app iOS/macOS
Construire la bibliothèque native :
Lien cactus-ios.xcframework à votre projet Xcode, puis :
Vous pouvez maintenant créer des applications iOS en utilisant le code suivant, mais pour voir les performances sur n'importe quel appareil pendant les tests, exécutez les tests cactus en branchant un iPhone à votre Mac puis en exécutant :
Les applications de démonstration Cactus s'étendront éventuellement pour utiliser vos ajustements personnalisés. De plus, cactus run permettra de brancher un téléphone, de sorte que la session interactive utilise les puces du téléphone ; de cette façon, vous pouvez tester avant de déployer complètement vos applications.
6. Utilisation dans une application Android
Construire la bibliothèque native :
Copier libcactus.so en app/src/main/jniLibs/arm64-v8a/, puis :
Vous pouvez maintenant créer des applications Android en utilisant le code suivant, mais pour voir les performances sur n'importe quel appareil pendant les tests, exécutez les tests cactus en branchant un téléphone Android à votre Mac puis en exécutant :
Les applications de démonstration Cactus s'étendront éventuellement pour utiliser vos ajustements personnalisés. De plus, cactus run permettra de brancher un téléphone, de sorte que la session interactive utilise les puces du téléphone ; de cette façon, vous pouvez tester avant de déployer complètement vos applications.
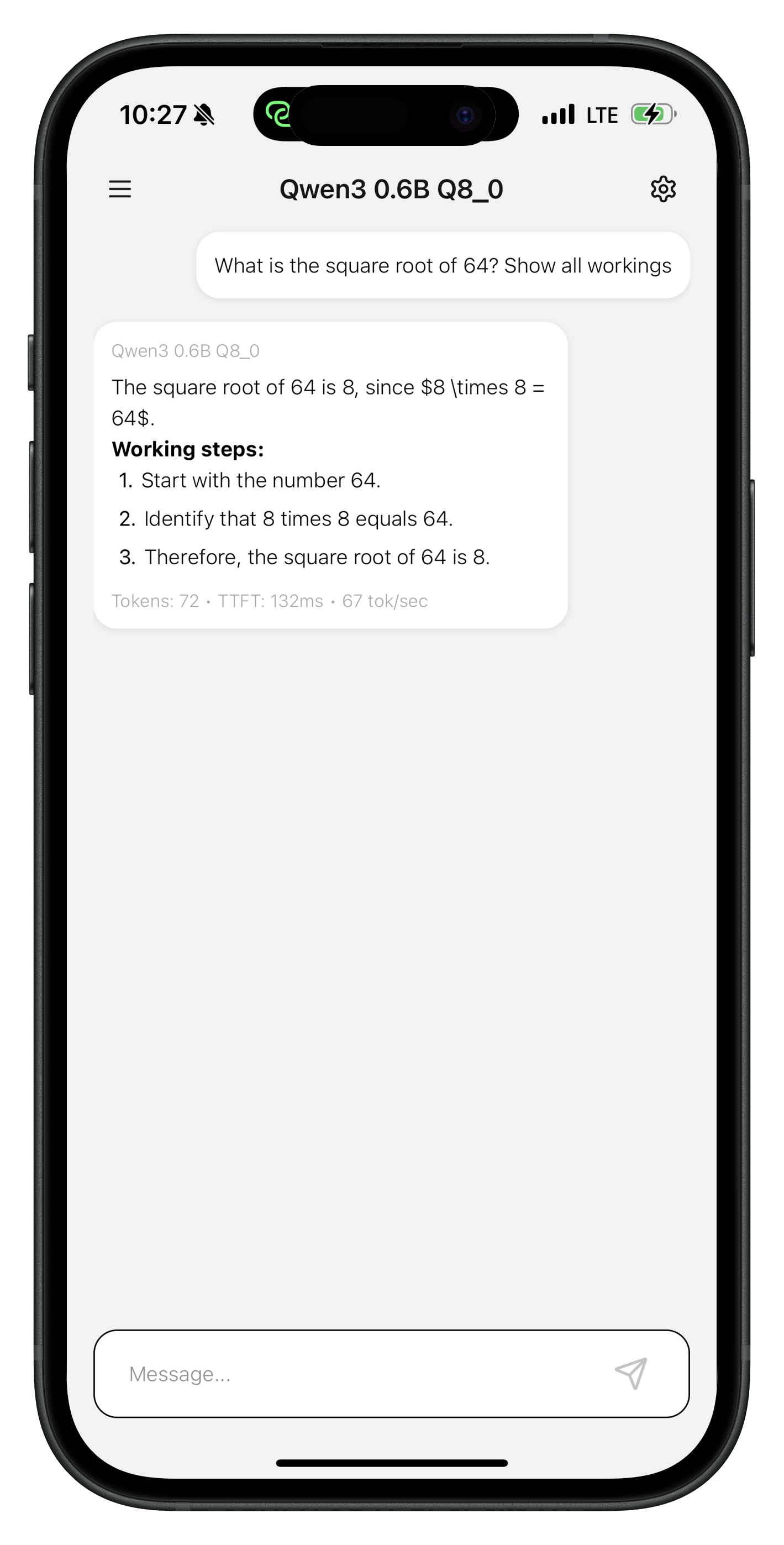
Ressources
Modèles de base pris en charge :
Qwen3, Gemma3, LFM2, SmolLM2Référence API complète : Moteur Cactus
En savoir plus et signaler des bugs : Cactus
Mis à jour
Ce contenu vous a-t-il été utile ?