

💧Liquid LFM2.5:如何运行与微调
在您的设备上本地运行并微调 LFM2.5 Instruct 与视觉模型!
动态 GGUFs
16-bit 指令型
⚙️ 使用指南
聊天模板格式
工具使用
🖥️ 运行 LFM2.5-1.2B-Instruct
📖 llama.cpp 教程(GGUF)
🦥 使用 Unsloth 微调 LFM2.5
Unsloth 的 LFM2.5 配置
训练设置
保存与导出
🎉 llama-server 服务与部署
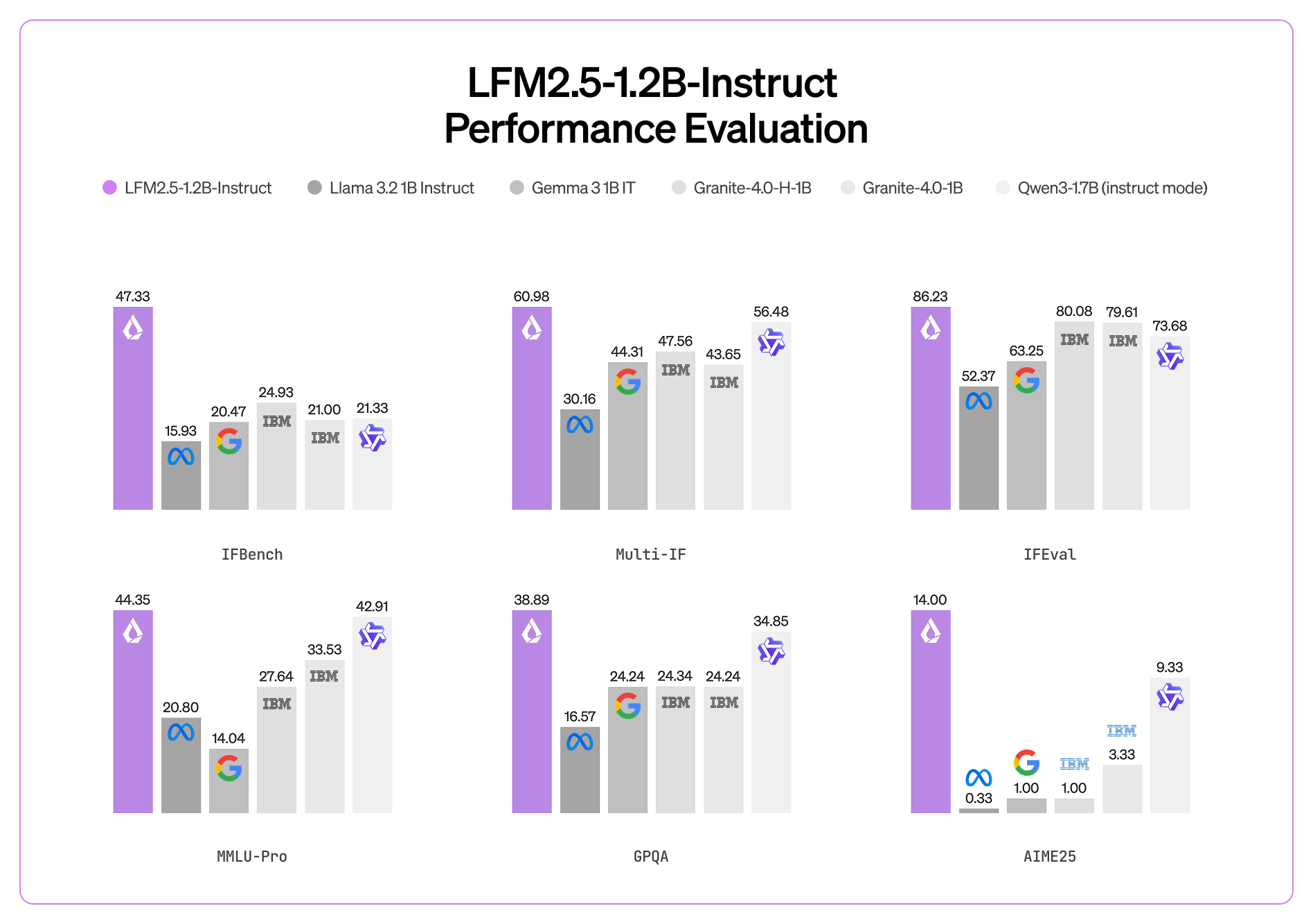
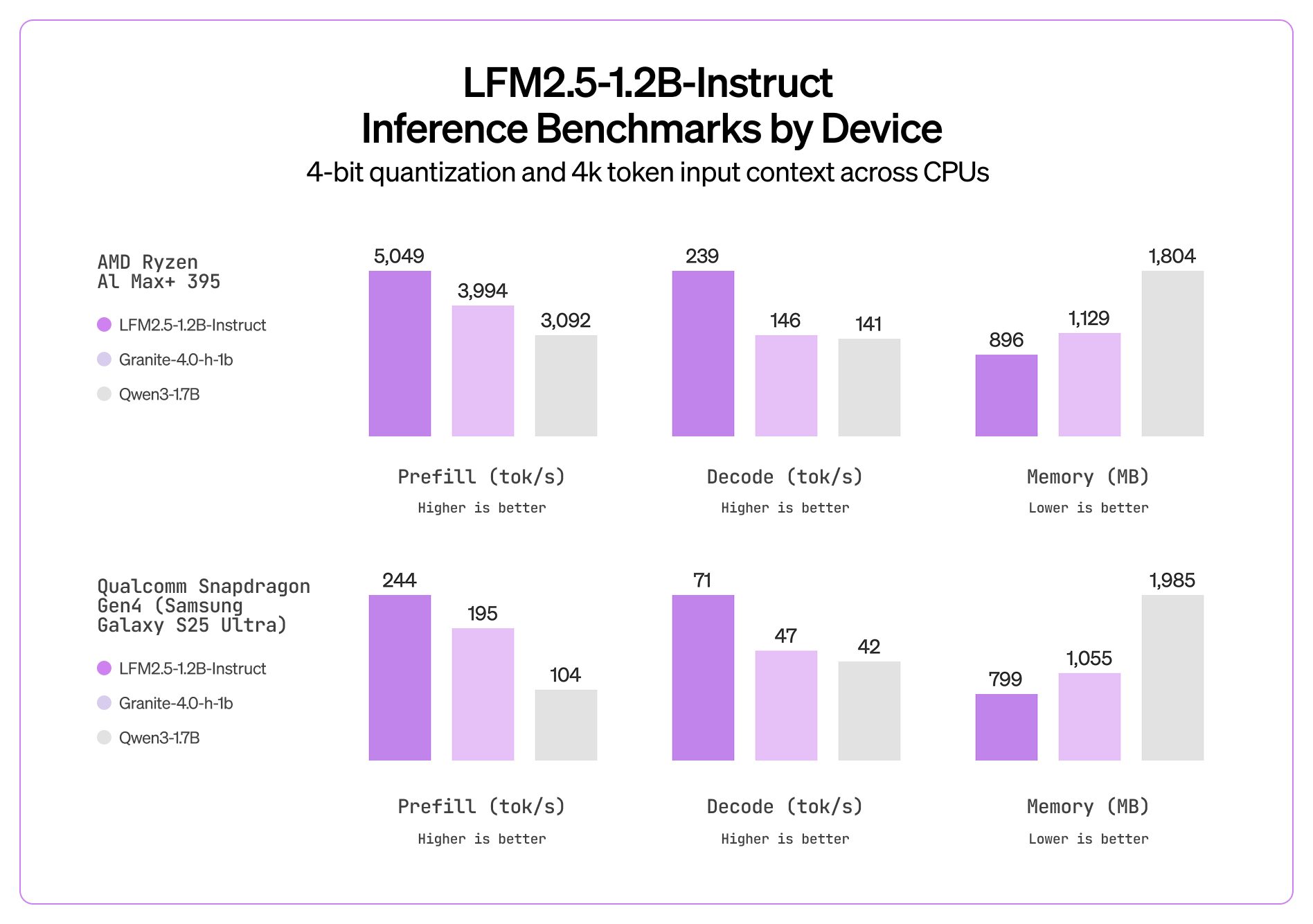
📊 基准测试
💧 Liquid LFM2.5-1.2B-VL 指南
动态 GGUFs
16-bit 指令型
⚙️ 使用指南
聊天模板格式
🖥️ 运行 LFM2.5-VL-1.6B
📖 llama.cpp 教程(GGUF)
🦥 使用 Unsloth 微调 LFM2.5-VL
Unsloth 的 LFM2.5 配置
训练设置
保存与导出
📊 基准测试
模型
MMStar
MM-IFEval
BLINK
InfoVQA(验证集)
OCRBench(v2)
RealWorldQA
MMMU(验证集)
MMMB(平均)
多语言 MMBench(平均)
📚 资源
最后更新于
这有帮助吗?