

💧Liquid LFM2.5: How To Run & Fine-tune
Run and fine-tune LFM2.5 Instruct and Vision locally on your device!
Dynamic GGUFs
16-bit Instruct
⚙️ Usage Guide
Chat Template Format
Tool Use
🖥️ Run LFM2.5-1.2B-Instruct
📖 llama.cpp Tutorial (GGUF)
🦥 Fine-tuning LFM2.5 with Unsloth
Unsloth Config for LFM2.5
Training Setup
Save and Export
🎉 llama-server Serving & Deployment
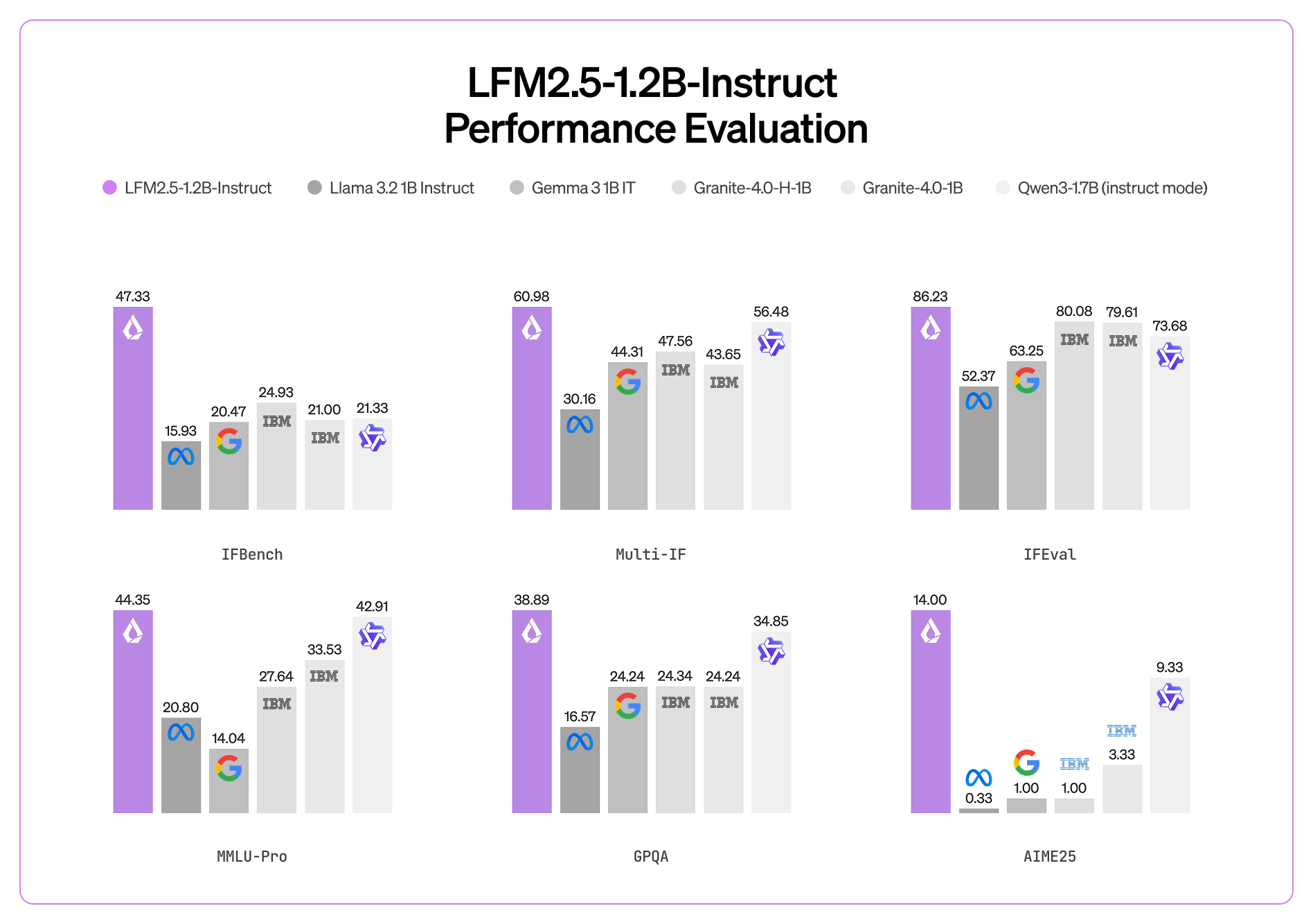
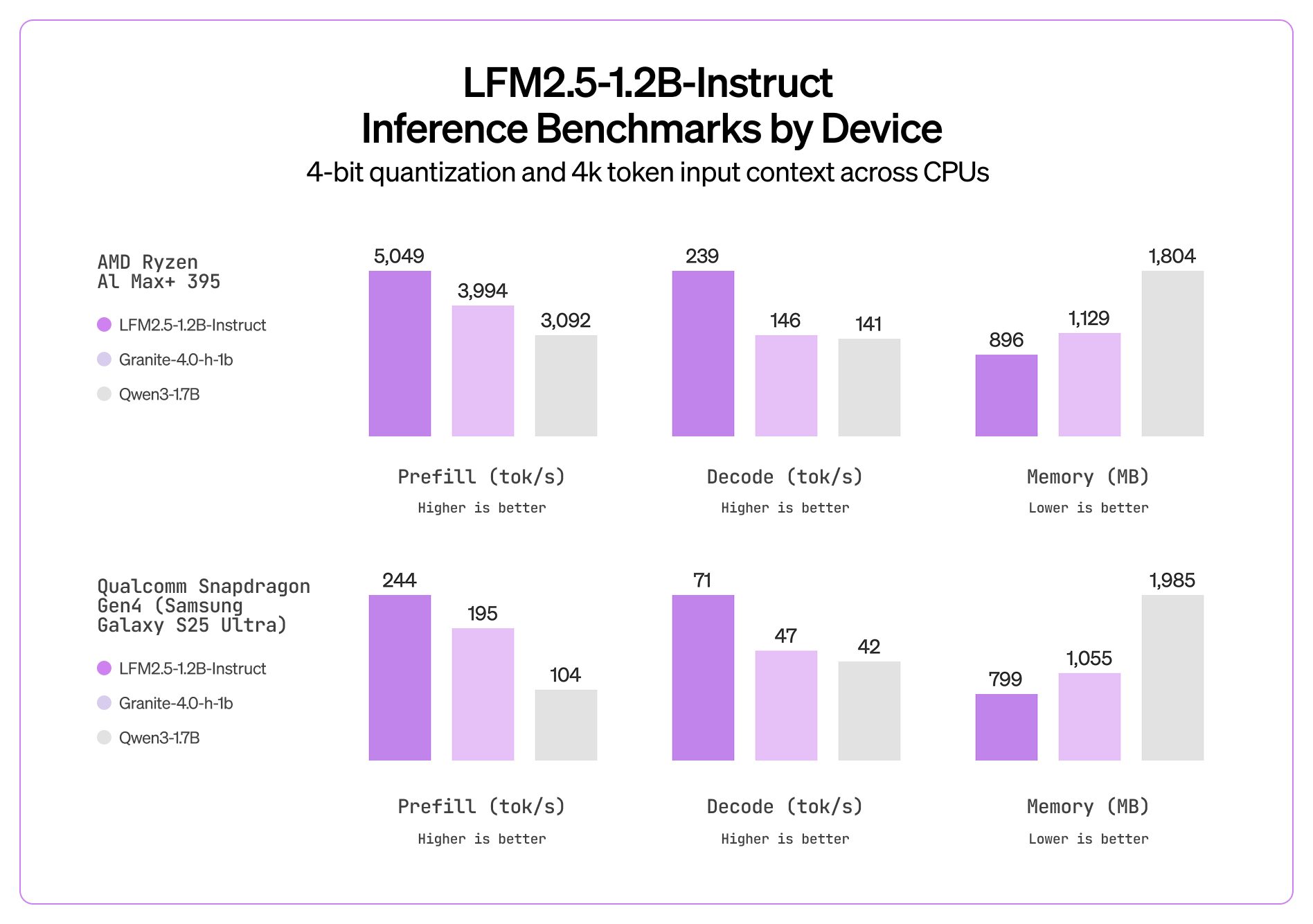
📊 Benchmarks
💧 Liquid LFM2.5-1.2B-VL Guide
Dynamic GGUFs
16-bit Instruct
⚙️ Usage Guide
Chat Template Format
🖥️ Run LFM2.5-VL-1.6B
📖 llama.cpp Tutorial (GGUF)
🦥 Fine-tuning LFM2.5-VL with Unsloth
Unsloth Config for LFM2.5
Training Setup
Save and Export
📊 Benchmarks
Model
MMStar
MM-IFEval
BLINK
InfoVQA (Val)
OCRBench (v2)
RealWorldQA
MMMU (Val)
MMMB (avg)
Multilingual MMBench (avg)
📚 Resources
Last updated
Was this helpful?