
Unsloth Studio runs 100% offline on your Mac and Windows device. Run GGUF and Safetensors models with tool-calling, web search, and OpenAI compatible API.
Compare models side by side and upload images, docs, audio, code files and more.


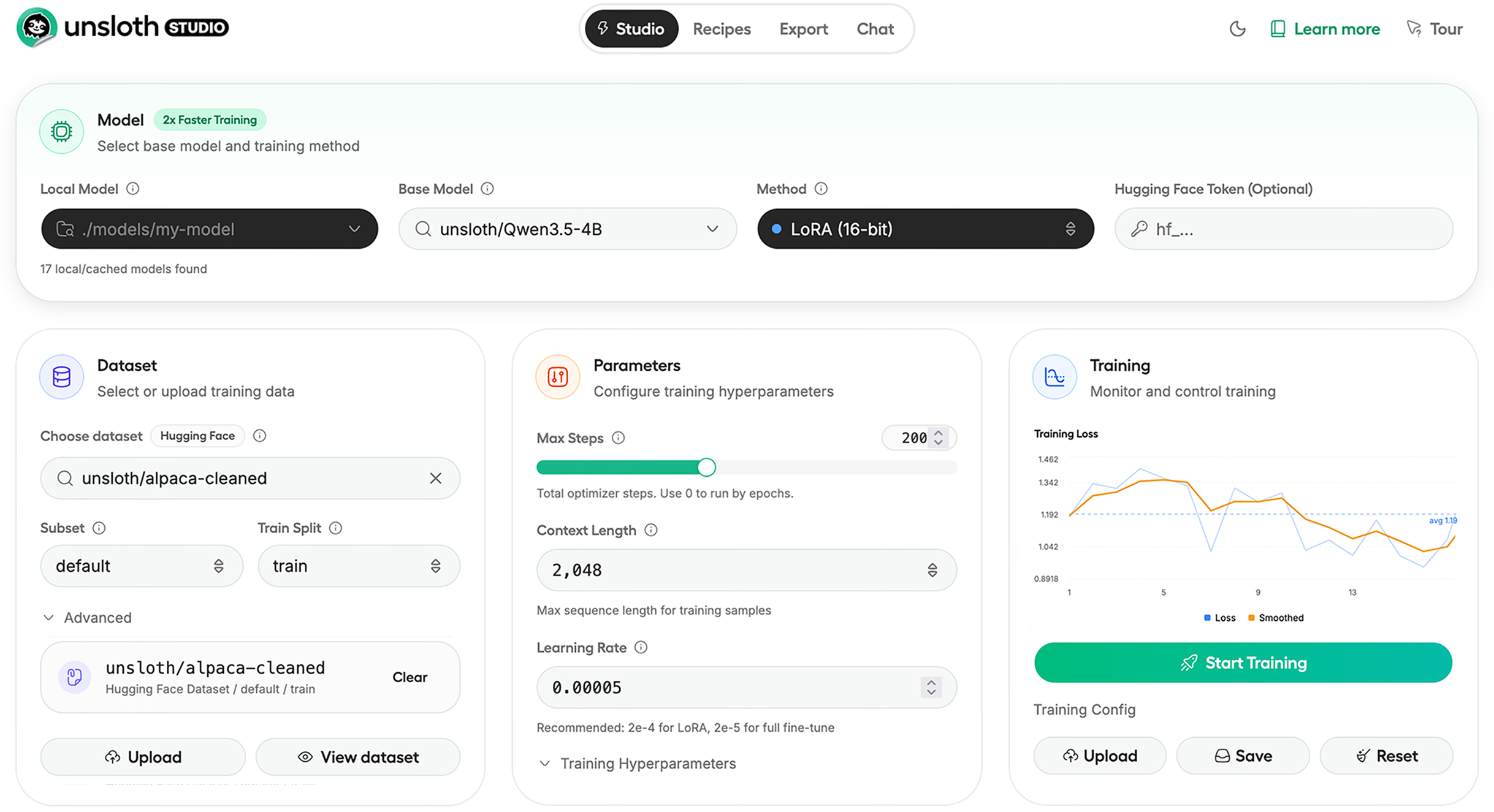
Auto-create datasets from PDF, CSV, JSON docs and start training with real-time observability.
Unsloth's custom kernels supports optimized training for LoRA, FP8, FFT, PT and 500+ models including text, vision, audio and embeddings.
Unsloth Studio lets LLMs run unlimited web search and execute Bash and Python, not just JavaScript. It sandboxes programs like Claude Artifacts so models can test code, generate files + verify answers with real computation.
E.g. Qwen3.5-4B searched 20+ websites and cited sources, with web search happening inside its thinking trace.


Data Recipes transforms your docs into useable datasets via graph-node workflow. Upload unstructured or structured files like PDFs, CSV and JSON. Unsloth Data Recipes auto turns documents into your desired formats.
Export any model, including your fine-tuned models, to safetensors, or GGUF for use with llama.cpp, vLLM, Ollama, and more.

Why not try our fully free open source version? Finetune 2X faster on a single NVIDIA GPU for free on Google Colab or Kaggle Notebooks.





