
pip install --upgrade --force-reinstall --no-cache-dir unsloth unsloth_zoo For newer GPUs like RTX 30x or higher, A100s, H100s etc, these GPUs have bfloat16 tensor cores, so this problem does not happen! But why?
For newer GPUs like RTX 30x or higher, A100s, H100s etc, these GPUs have bfloat16 tensor cores, so this problem does not happen! But why? Float16 can only represent numbers up to 65504, whilst bfloat16 can represent huge numbers up to 10^38! But notice both number formats use only 16bits! This is because float16 allocates more bits so it can represent smaller decimals better, whilst bfloat16 cannot represent fractions well.
Float16 can only represent numbers up to 65504, whilst bfloat16 can represent huge numbers up to 10^38! But notice both number formats use only 16bits! This is because float16 allocates more bits so it can represent smaller decimals better, whilst bfloat16 cannot represent fractions well.Preliminary support for full-finetuning and 8-bit finetuning - set full_finetuning = True and load_in_8bit = True respectively. Both will be optimized further in the future! A reminder you will need more powerful GPUs!
New Unsloth Auto Model support - nearly all models are now supported! Unsloth now supports vision and text models out of the box, without the need for custom implementations (and all are optimized). This allows for a faster and less error prone + more stable/streamlined finetuning experience.
We also support: Qwen's QwQ-32B, Mistral's Mixtral, IBM's 3.2 Granite, Microsoft's Phi-4-mini, Cohere's c4ai-command-a, AllenAI's OLMo-2 and every other transformer-style model out there! We also uploaded dynamic 4-bt and GGUFs for these models.
Many multiple optimizations in Unsloth allowing a further +10% less VRAM usage, and >10% speedup boost for 4-bit (on top of our original 2x faster, 70% less memory usage). 8-bit and full finetuning also benefit.
Windows support via pip install unsloth should function now! Utilizes 'pip install triton-windows' which provides a pip installable path for Triton.
Conversions to llama.cpp GGUFs for 16bit and 8bit now DO NOT need compiling! This solves many many issues, and this means no need to install GCC, Microsoft Visual Studio etc.
Vision fine-tuning: Train on completions / responses only for vision models supported! Pixtral and Llava finetuning are now fixed! In fact nearly all vision models are supported out of the box! Vision models now auto resize images which stops OOMs and also allows truncating sequence lengths.
GRPO in Unsloth now allows non Unsloth uploaded models to be in 4bit as well - reduces VRAM usage a lot! (ie using your own finetune of Llama)
New training logs and infos - training parameter counts, total batch size
Complete gradient accumulation bug fix coverage for all models!
Here's an in depth analysis we did for Gemma 3's architecture:
1. 1B text only, 4, 12, 27B Vision + text. 14T tokens
2. 128K context length further trained from 32K
3. Removed attn softcapping. Replaced with QK norm
4. 5 sliding + 1 global attn
5. 1024 sliding window attention
6. RL - BOND, WARM, WARP
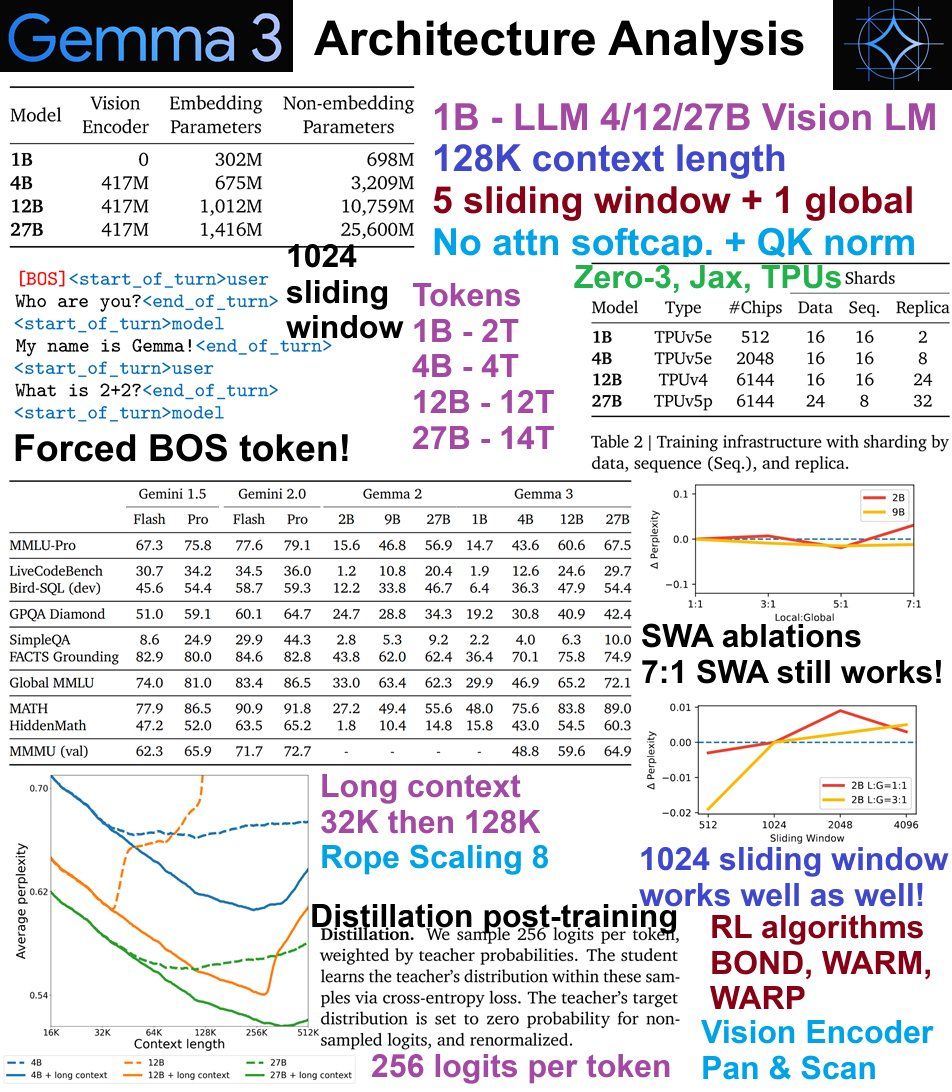
1. Architectural differences to Gemma 2:
More sliding windows are added to reduce KV cache load! A 5:1 ratio was found to work well, and ablations show 7:1 even work ok! SWA is 1024 - ablations show 1024 to 2048 work well.
2. Training, post-training
Gemma-3 uses TPUs, and Zero-3 like algos with JAX. 27B was trained on 14 trillion tokens. 12B = 12T, 4B = 4T and 1B = 2T tokens. All used distillation in the RL / post-training stage. Sampled 256 logits per token from a larger instruct model (unsure which - maybe a closed source one?). Used RL algos like BOND, WARM and WARP.
3. Chat template now forces a BOS token! Uses <start_of_turn>user and <start_of_turn>model. 262K vocab size. SentencePiece tokenizer with split digits, preserved whitespace & byte fallback.
4. Long Context & Vision Encoder:
Trained from 32K context, then extended to 128K context. RoPE Scaling of 8 was used. Pan & Scan algo was used for vision encoder. Vision encoder operates at a fixed resolution of 896 * 896. Uses windowing during inference time to allow other sizes.
We uploaded Unsloth Dynamic 4-bit quants for Gemma 3, delivering a significant accuracy boost over standard 4-bit - especially for vision models, where the difference is most pronounced. As shown in our previous Qwen2-VL experiments, our dynamic quants provided substantial accuracy gains with only a 10% increase in VRAM usage.
A great benchmark example is our dynamic 4-bit quant for Phi-4, submitted to Hugging Face's OpenLLM Leaderboard. It scored nearly as high as our 16-bit version—and outperformed both standard BnB 4-bit and Microsoft’s official 16-bit model, particularly on MMLU.
Also see the activation and weight error analysis plots for Gemma 3 (27B) compared to Unsloth Dynamic quants further below:



