Mistral released NeMo, a 12 billion open model yesterday! It has multilingual support, has native tool support and is one of the largest open models to fit exactly in a free Google Colab GPU instance with Unsloth for finetuning, which you can access here.
Here's a list of all the most important updates:
Found & fixed 3 issues in NeMo
You can now use CSV/Excel files + multi column datasets to finetune with
All models now have long context support including Gemma 2, Mistral & Qwen2
Torch 2.5, Triton 3 preliminary, Flex Attention support
Train On Completions / Responses only
Mistral NeMo (12B)
Unsloth makes finetuning Mistral Nemo (12B) 2x faster and use 60% less VRAM, with 3-4x longer context length supports than HF+FA2. By reducing actual FLOPs, writing kernels in OpenAI’s Triton language, and having a custom backprop engine, we allow you to finetune in a free Colab 16GB GPU instance exactly! Try our free Colab notebook or our Kaggle notebook.
We also uploaded pre-quantized 4bit models for 4x faster downloading to Hugging Face which includes Mistral NeMo Instruct and Base.
Mistral NeMo (12B) benchmarks
Model
VRAM
🦥Unsloth speed
🦥 VRAM reduction
🦥 Longer context
🤗Hugging Face+FA2
Mistral NeMo
24GB
2x
60%
4x longer
1x
Mistral NeMo
40GB
1.9x
58%
4x longer
1x
We tested using the Alpaca Dataset, a batch size of 2, gradient accumulation steps of 4, rank = 32, and applied QLoRA on all linear layers (q, k, v, o, gate, up, down).
NeMo Fixes
When we were implementing Mistral in Unsloth, we found 3 issues, and are working with the Hugging Face and Mistral team to fix them! We fixed them all in Unsloth already:
EOS token was always added The original Mistral upload appended an EOS token to every output, causing inference and finetuning to break entirely. Finetuning it will simply output the EOS token. The fantastic HF team collaborated with us to solve this issue in transformers. We’re unsure if Mistral’s own libraries do this. Unsloth has this fixed already.
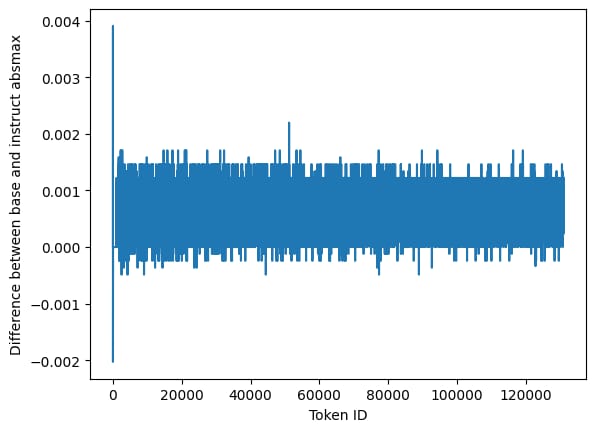
Base model has possible untrained EOS token </s> We always strive for perfect finetunes in Unsloth, and randomly when finetuning the Base Nemo model, Unsloth errored out and warned some tokens were untrained (so nearly all 0s). This might cause NaNs or infinities in some finetuning runs.
So we compared the Instruct and Base model weights, and found the largest differences in magnitude were the <s> and </s> tokens (as seen in the graph above). We then found the </s> token specifically in the base model to have an absolute maximum value of 1.1219e-23, whilst the </s> in the instruct model is 2.0294e-03.
We’re collaborating with the Mistral team to understand if the EOS token </s> is untrained, which might cause issues for inference or finetuning.
Wrong Head Dimension still proceeds The Mistral model uses a lopsided head dim of 128 still even though the hidden size of 5120 divided by the number of attention heads (32) is 160. Transformers fixed this in their nightly release, but people who do not upgrade transformers will still be able to load the model in their old transformers versions. Below the first is the “wrong” version, whilst the second is the “correct” version. In Unsloth, we auto patch this for you.
✔️ 1 more fix in Gemma 2
Now we're going to talk about another new fix for Google's newest open model: Gemma 2. After collaborating with the Gemma and Google teams on fixing a few bugs in Gemma 2 (described here), the Gemma team advised the OSS community that Gemma-2 9b’s query_pre_attn_scalar should be 256 and not 224. We collaborated with the llama.cpp team and Hugging Face to patch and fix this - see our Hugging Face commit and llama.cpp commit.
Auto Export to Ollama
To use, create and customize your chat template with a dataset and Unsloth will automatically export the finetune to Ollama with automatic Modelfile creation. We also created a 'Step-by-Step Tutorial on How to Finetune Llama-3 and Deploy to Ollama'. Check out our Ollama Llama-3 Alpaca and CSV/Excel Ollama Guide notebooks.
Unlike regular chat templates that use 3 columns, Ollama simplifies the process with just 2 columns: instruction and output. And with Ollama, you can save, run, and deploy your finetuned models locally on your own device.
Previously, we presented in Ollama's Discord server with Sebastien to discuss emotions in fine-tuning, and the new update. Watch Sebastien's amazing presentation here. A huge thank you to the incredible Ollama team and Sebastien for making this possible!
A video tutorial featuring this new update will be released with Unsloth Studio (Beta) - our new UI (in collaboration with Sebastien) which will run on Google Colab, Hugging Face and locally.
📖 New Documentation
Introducing our new Documentation site which has all the most important info about Unsloth in one place. If you'd like to contribute, please contact us! Docs: https://docs.unsloth.ai/
🌠 CSV/Excel + multicolumn support
One of the most important aspects of the release is how your dataset can now have as many columns as possible rather than just 2 or 3.
A big issue is for ChatGPT style assistants, we only allow 1 instruction / 1 prompt, and not multiple columns / inputs. For example in ChatGPT, you can see we must submit 1 prompt, and not multiple prompts. This essentially means we have to "merge" multiple columns into 1 large prompt for finetuning to actually function!
Other finetuning libraries require you to manually prepare your dataset for finetuning, by merging all your columns into 1 prompt. In Unsloth, we simply provide the function called to_sharegpt which does this in 1 go! Try out our new finetuning notebook for uploading CSV or Excel files and read our new Tutorial Guide.
🧶Gemma, Mistral, Qwen long context
We now allow you to finetune Gemma 2, Mistral, Mistral NeMo, Qwen2 and more models with “unlimited” context lengths through RoPE linear scaling through Unsloth. Coupled with our 4x longer context support, Unsloth can do extremely long context support!
💡 Train on Completions / Responses only
We now support training on completions / responses and not on the inputs. To learn how to use it, see here.
⚡ 2-4x Faster downloads
We now enable downloading Hugging Face models 2-4x faster if you are on a high bandwidth server (like Colab). We use Hugging Face Hub’s fast transfer methodology by default.
🔥 Torch 2.5, Triton 3, Flex Attention
Unsloth should support torch 2.5 and Triton 3 out of the box. We are also working with Pytorch on Flex Attention support especially for long context finetuning for Gemma-2!
💕 Thank you!
A huge thank you to Sebastien, Cam, the Ollama team & the Unsloth community for helping us out with this release! Without your help like catching bugs, this wouldn't have been possible.
Huge shout out to: Fernando, pacozaa, Edd, loss_flow, x1250, John & user799595 who are new supporters! 🙏
As always, be sure to join our Discord server for help or just to show your support! You can also join our Reddit page or follow us on Twitter and Substack.