Fixing All Gemma Bugs
Mar 6, 2024 • By Daniel & Michael
Mar 6, 2024
•
By Daniel & Michael
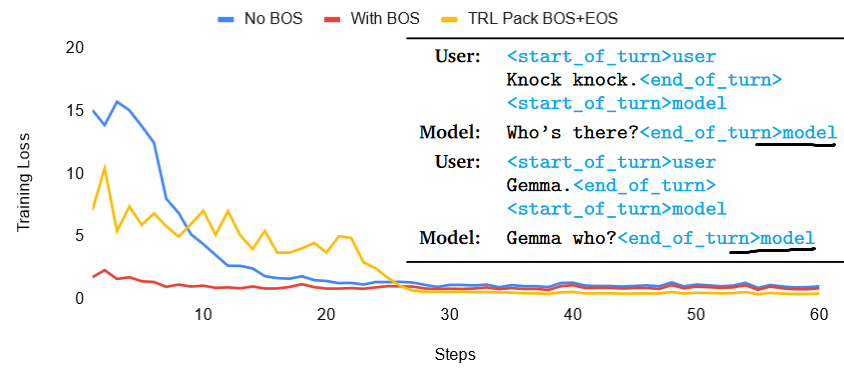
1. Must add <bos>
2. Paper typo? <end_of_turn>model
3. sqrt(3072)=55.4256 but bfloat16 is 55.5
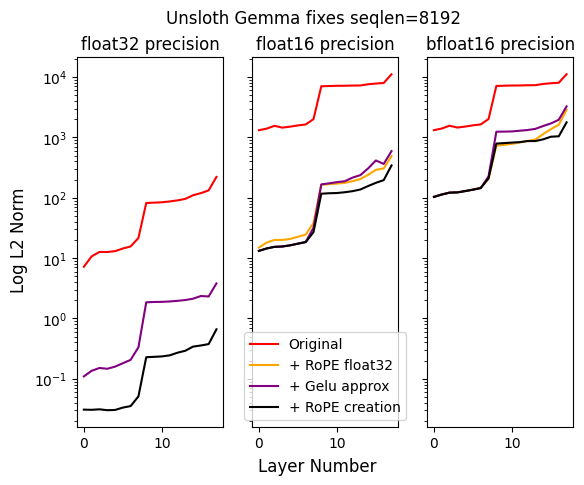
4. Layernorm (w+1) should be done in float32
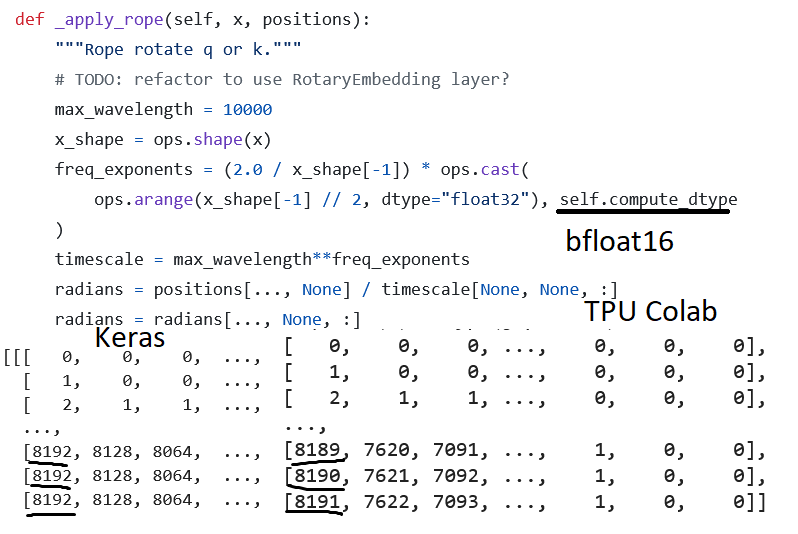
5. Keras mixed_bfloat16 RoPE is wrong
6. RoPE is sensitive to a*(1/x) vs a/x
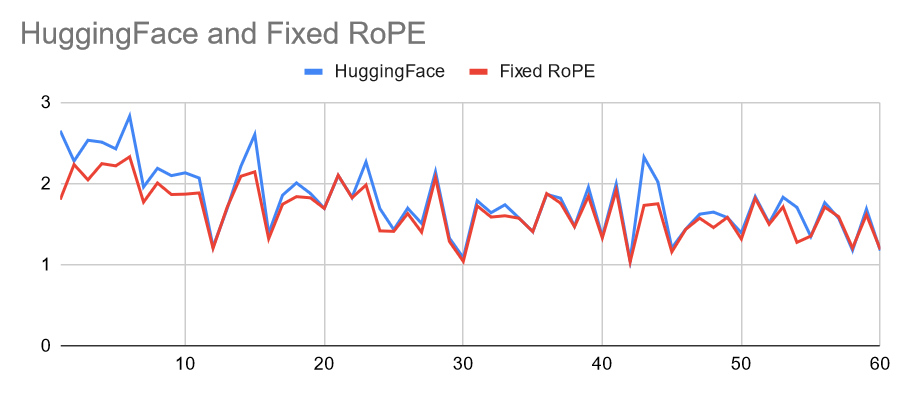
7. RoPE should be float32. Fixed it in HF 4.38.2.
8. GELU should be approx tanh not exact. Ongoing PR