Unsloth’s new release allows you to easily continually pretrain LLMs 2x faster and use 50% less VRAM than Hugging Face + Flash Attention 2 QLoRA. We've released a free Colab notebook to continually pretrain Mistral v0.3 7b to learn a new language like Korean and another Colab for text completion!We provide the following insights:
You should finetune the input and output embeddings.
Unsloth offloads embeddings to disk to save VRAM.
Use different learning rates for the embeddings to stabilize training.
Use Rank stabilized LoRA.
We can improve upon the paper “LoRA Learns Less and Forgets Less”, reducing the red loss curve to the green one as shown below:
Continued pretraining benchmarks
Model
VRAM
🦥Unsloth speed
🦥 VRAM reduction
🦥 Longer context
🤗Hugging Face+FA2
Llama-3 8B
24GB
2x
52%
3x longer
1x
Llama-3 70B
80GB
1.9x
49%
6x longer
1x
We used QLoRA and trained on all linear layers (including the embed_tokens and lm_head) and used a rank of 256 on a L4 GPU.
♻️ But what is Continued Pretraining?
Continued or continual pretraining (CPT) is necessary to “steer” the language model to understand new domains of knowledge, or out of distribution domains. Base models like Llama-3 8b or Mistral 7b are first pretrained on gigantic datasets of trillions of tokens (Llama-3 for eg is 15 trillion). But sometimes these models have not been well trained on other languages, or text specific domains, like law, medicine or other areas. So continued pretraining (CPT) is necessary to make the language model learn new tokens or datasets.
📖 LoRA Learns Less & Forgets Less
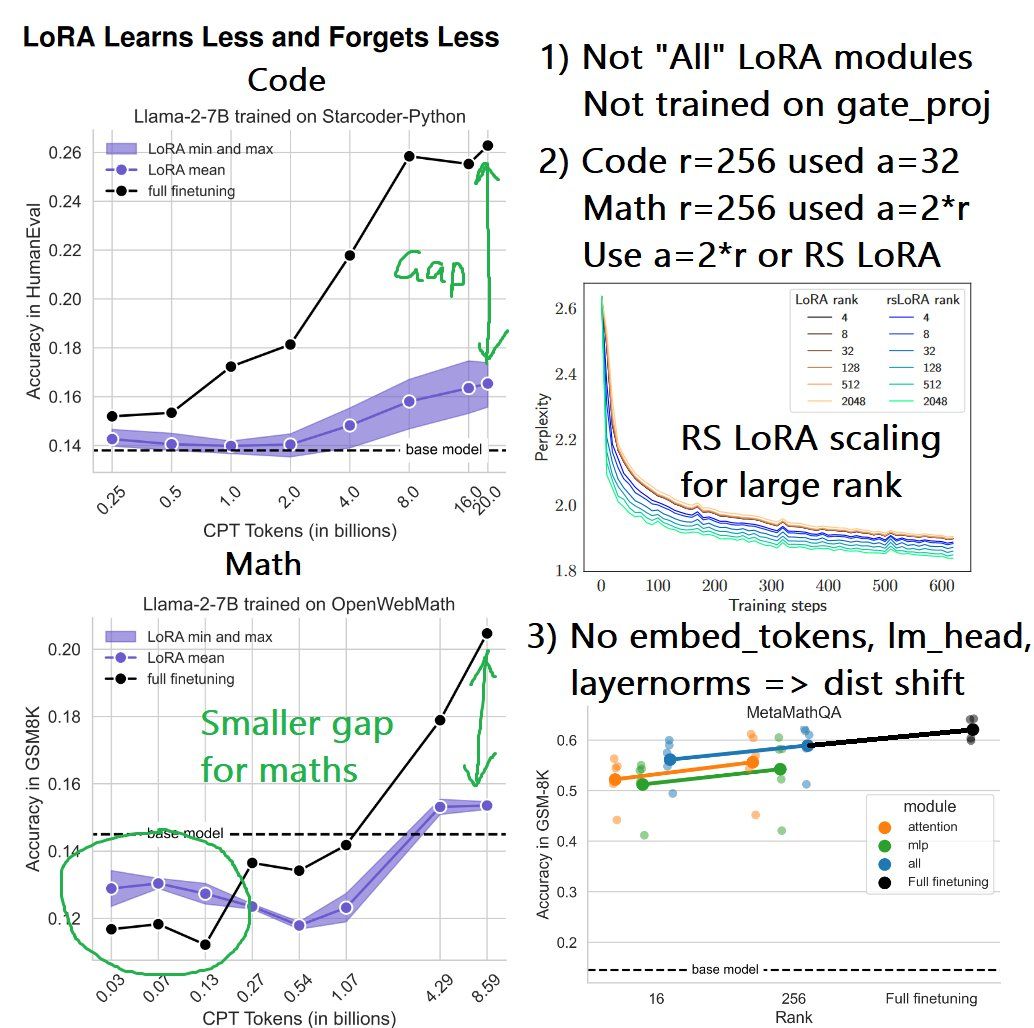
A recent paper showed how using LoRA is inferior to full finetuning when doing continual pretraining. We tweeted about how we can improve upon the paper here:
Main issues and suggested solutions from paper:
The paper did not finetune the gate projection matrix, and so did not finetune on all linear layers. See page 3’s footnote. Only the attention, and up + down matrices are fine tuned. Solution: Train on the gate projection!
The paper showed how Llama-2 performed well on maths, but not code - this is because the lm_head & embed_tokens weren't trained, so domain data distribution shifts are not modelled. Solution: Train on the embed_tokens and lm_head!
Code rank of 256 used an alpha of 32. The rsLoRA paper showed that for larger ranks, one must use alpha/sqrt(rank) instead of alpha/rank. Solution: Use rsLoRA!
Use LoftQ or PiSSA for better initializations or LoRA+ or DoRA for more advanced finetunes - it’s much harder to finetune, and does not interact well with rsLoRA or other methods.
We show if we employ all our suggestions step by step, we can carefully reduce the training loss.
🧑🤝🧑 Decoupled Learning Rates
Interestingly, blinding training on the lm_head and embed_tokens does even worse! We show we must use a smaller learning rate for the lm_head and embed_tokens, and Unsloth handles this with our new UnslothTrainer and UnslothTrainingArguments. Simply set embedding_learning_rate to be a smaller number than the normal learning_rate. For example, 10x smaller or 2x smaller. We found this to be highly effective.
💕 Thank you!
Feel free to support us via our Ko-fi donation page. Huge shout out to: Steven, Edd, Jack and Jun who are new supporters! 🙏
As always, be sure to join our Discord server for help or just to show your support! You can also follow us on Twitter and Substack.
✏️Appendix
We provide reproducible Colabs for each of our experiments: