


| 后端 | 优化 |
|---|---|
| grouped_mm | torch._grouped_mm - 从 T4 一直到 B200 都可用,但针对 H100+ 进行了优化。 |
| unsloth_triton | Unsloth Triton 内核——会在 A100 及更旧的 PyTorch 版本上自动启用。 |
| native_torch | 原生 PyTorch。它慢 12 倍,但我们的显存减少仍然存在! |


与 transformers v4 的比较
| 上下文长度 | Unsloth(毫秒) | TF v5(毫秒) | Unsloth 显存(GB) | TF v5 显存(GB) | 提速 | 显存节省 | Rank | Unsloth 预热(毫秒) | TRL 预热(毫秒) |
|---|---|---|---|---|---|---|---|---|---|
| 1024 | 275.35 | 376.99 | 40.91 | 43.88 | 1.4 倍 | 6.76% | 8 | 2601.17 | 615.62 |
| 2048 | 292.88 | 696.57 | 41.83 | 44.93 | 2.4 倍 | 6.89% | 8 | 4996.62 | 928.42 |
| 4096 | 370.30 | 1785.89 | 43.68 | 49.86 | 4.8 倍 | 12.39% | 8 | 6648.94 | 2130.33 |
| 8192 | 712.33 | 5226.86 | 47.43 | 73.80 | 7.3 倍 | 35.73% | 8 | 9632.44 | 5472.66 |
| 16384 | 1775.80 | OOM | 55.13 | OOM | 不适用 | 不适用 | 8 | 12696.26 | 不适用 |
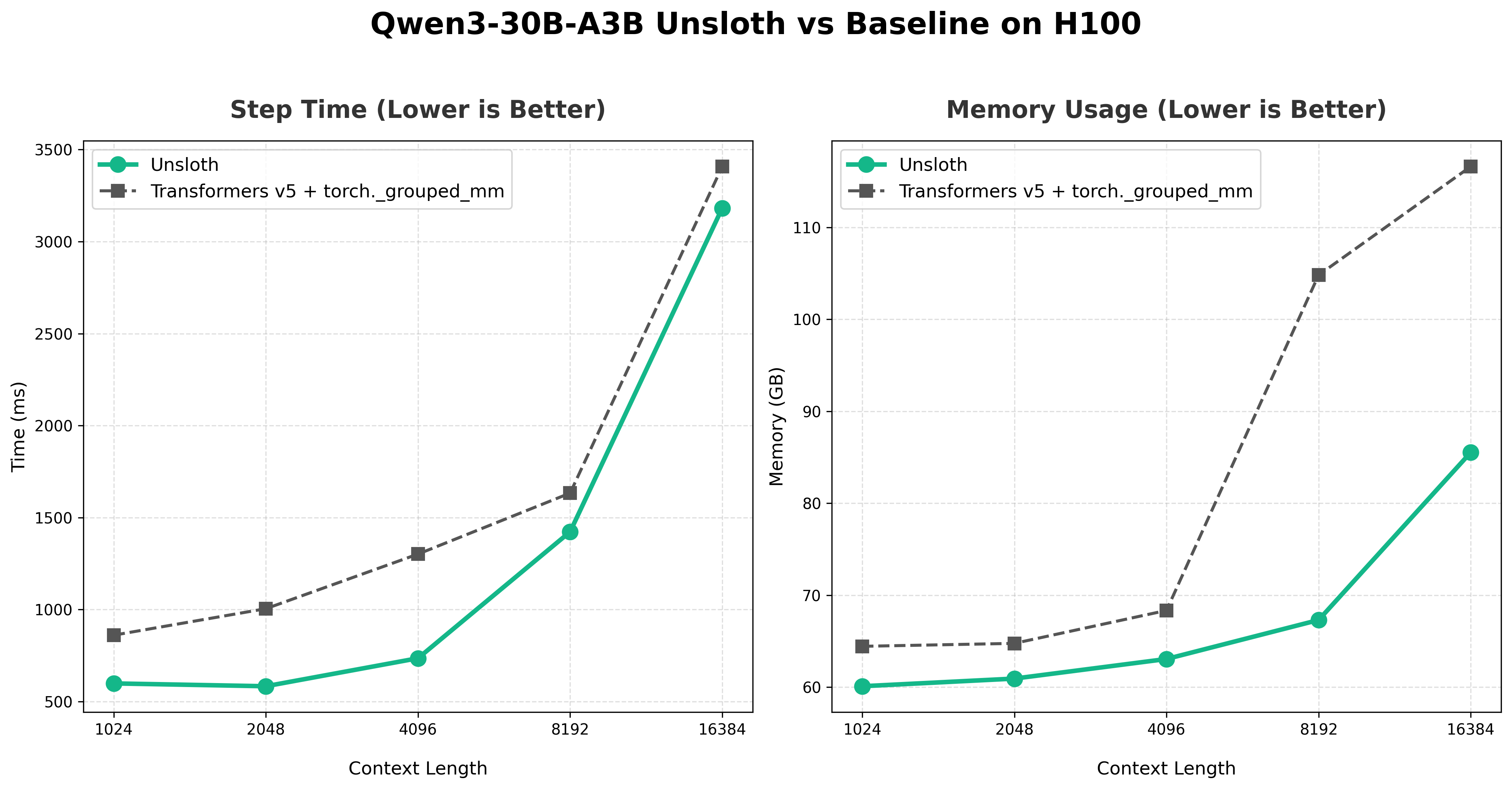
| 上下文长度 | Unsloth(毫秒) | TF v5(毫秒) | Unsloth 显存(GB) | TF v5 显存(GB) | 提速 | 显存节省 | Rank |
|---|---|---|---|---|---|---|---|
| 1024 | 366.3 | 628.3 | 80.88 | 104.80 | 1.7x | 2.06% | 8 |
| 2048 | 467.0 | 745.3 | 80.88 | 104.81 | 1.6x | 2.57% | 8 |
| 4096 | 711.6 | 975.5 | 80.89 | 104.80 | 1.4 倍 | 5.08% | 8 |
| 8192 | 1376.6 | 1633.5 | 80.90 | 104.81 | 1.2x | 9.17% | 8 |
| 16384 | 3182.2 | 3407.9 | 85.53 | 116.61 | 1.1x | 15.26% | 8 |

| 上下文长度 | Unsloth(毫秒) | TF v5(毫秒) | Unsloth 显存(GB) | TF v5 显存(GB) | 提速 | 显存节省 | Rank | Unsloth 预热(毫秒) | TRL 预热(毫秒) |
|---|---|---|---|---|---|---|---|---|---|
512 | 1145.0 | 2992.1 | 57.81 | 60.89 | 2.6 倍 | 6.51% | 8 | 13317.46 | 893.04 |
| 1024 | 1298.9 | 3323.3 | 58.76 | 62.55 | 2.6 倍 | 6.22% | 8 | 12895.28 | 937.37 |
| 2048 | 1831.9 | 4119.3 | 60.09 | 67.32 | 2.3 倍 | 9.46% | 8 | 12531.37 | 1039.45 |
| 4096 | 2883.9 | 5646.1 | 63.34 | 76.78 | 2 倍 | 14.83% | 8 | 7671.60 | 1643.26 |
| 上下文长度 | Unsloth(毫秒) | TF v5(毫秒) | TF v4(毫秒) | 提速 |
|---|---|---|---|---|
| 1024 | 275.35 | 376.99 | 2111.18 | 1.37 倍 |
| 2048 | 292.88 | 696.57 | 2626.80 | 2.38 倍 |
| 4096 | 370.30 | 1785.89 | 4027.93 | 4.82 倍 |
| 8192 | 712.33 | 5226.86 | 8513.52 | 7.34 倍 |
| 16384 | 1775.80 | OOM | OOM | 不适用 |
| 上下文长度 | Unsloth 显存(GB) | TF v5 显存(GB) | TF v4 显存(GB) | 显存节省 |
|---|---|---|---|---|
| 1024 | 40.91 | 43.88 | 89.75 | 6.76% |
| 2048 | 41.83 | 44.93 | 90.47 | 6.89% |
| 4096 | 43.68 | 49.86 | 92.72 | 12.39% |
| 8192 | 47.43 | 73.80 | 100.3 | 35.73% |
| 16384 | 55.13 | OOM | OOM | 不适用 |
